Department of Philosophical, Pedagogical and Economic-Quantitative Sciences, University of Chieti-Pescara, Italy
(A contribution to the: JASSS-Covid19-Thread)
When writing this document, few countries have made significant progress in vaccinating their population while many others still move first steps.
Despite the importance of COVID-19 adverse effects on society, there seems to be too little debate on the best option for progressing the vaccination process after the front-line healthcare personnel has been immunized.
The overall adopted strategies in the front-runner countries prioritize people using their health fragility, and age. For example, this strategy’s effectiveness is supported by Bubar et al. (2021), who provide results based on a detailed age-stratified Susceptible, Exposed, Infectious, Recovered (SEIR) model.
During the Covid infection outbreak, the importance of families in COVID diffusion was stressed by experts and media. This observation motivates the present effort, which investigates if considering family size among the vaccine prioritization strategy can have a role.
This document describes an ABM model developed with the intent of analyzing the question. The model is basic and has the essentials features to investigate the issue.
As highlighted by Squazzoni et al. (2020) a careful investigation of pandemics requires the cooperation of many scientists from different disciplines. To ease this cooperation and to the aim of transparency (Barton et al. 2020), the code is made publicly available to allow further developments and accurate parameters calibration to those who might be interested. (https://github.com/gfgprojects/abseir_family)
The following part of the document will sketch the model functioning and provide some considerations on families’ effects on vaccination strategy.
Brief Model Description
The ABSEIR-family model code is written in Java, taking advantage of the Repast Simphony modeling system (https://repast.github.io/).
Figure 1 gives an overview of the current development state of the model core classes.
Briefly, the code handles the relevant events of a pandemic:
- the appearance of the first case,
- the infection diffusion by contacts,
- the introduction of measures for diffusion limitation such as quarantine,
- the activation and implementation of the immunization process.
The distinguishing feature of the model is that individuals are grouped in families. This grouping allows considering two different diffusion speeds: fast among family members and slower when contacts involve two individuals from different families.
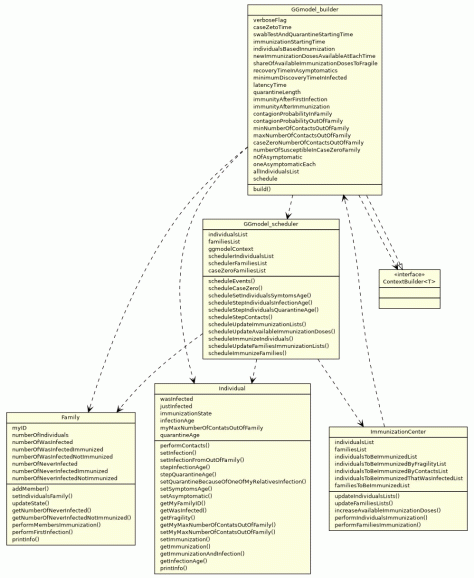
Figure 1: relationships between the core classes of the ABSEIR-family model and their variables and methods.
It is perhaps worth describing the evolution of an individual state to sketch the functioning of the model.
An individual’s dynamic is guided by a variable named infectionAge. In the beginning, all the individuals have this variable at zero. The program increases the infectionAge of all the individuals having a non zero value of this variable at each time step.
When an individual has contact with an infectious, s/he can get the infection or not. If infected, the individual enters the latency period, i.e. her/his infectionAge is set to 1 and the variable starts moving ahead with time, but s/he is not infectious. Individuals whose infectionAge is greater than the latency period length (ll ) become infectious.
At each time step, an infectious meets all her/his family members and mof randomly chosen non-family members. S/he passes on the infection with probability pif to family members and pof to non-family members. The infection can be passed on only if the contacted individual’s infectionAge equals zero and if s/he is not in quarantine.
The infectious phase ends when the infection is discovered (quarantine) or when the individual recovers i.e., the infectionAge is greater than the latency period length plus the infection length parameter (li).
At the present stage of development, the code does not handle the virus adverse post-infection evolution. All the infected individuals in this model recover. The infectionAge is set at a negative value at recovery because recovereds stay immune for a while (lr). Similarly, vaccination set the individual’s infectionAge to a (high) negative value (lv).
At the present state of the pandemic evolution it is perhaps useful to use the model to get insights into how the family size could affect the vaccination process’s effectiveness. This will be attempted hereafter.
Highlighting the relevance of families size by an ad-hoc example
The relevance of family size in vaccination strategy can be shown using the following ad-hoc example.
Suppose there are two covid-free villages (say village A and B) whose health authorities are about to start vaccinations to avoid the disease spreading.
Villages are identical in the other aspects except for the family size distribution. Each village has 50 inhabitants, but village A has 10 families with five components each, while village B has two five members families and 40 singletons. Five vaccines arrive each day in each village.
Some additional extreme assumptions are made to make differences straightforward.
First, healthy family members are infected for sure by a member who contracted the virus. Second, each individual has the same number of contacts (say n) outside the family and the probability to pass on the virus in external contacts is lower than 1. Symptoms take several days before showing up.
Now, the health authority are about to start the vaccination process and has to decide how to employ the available vaccines.
Intuition would suggest that Village B’s health authority should immunize large families first. Indeed, if case zero arrives at the end of the second vaccination day, the spread of the disease among the population should be limited because the virus can be passed on by external contacts only; and the probability of transmitting the virus in external contacts is lower than in the family.
But, should this strategy be used even by village A health authority?
To answer this question, we compare the family-based vaccination strategy with a random-based vaccination strategy. In a random-based vaccination strategy, we expect one members to be immunized in each family at the end of the second vaccination day. In the family-based vaccination strategy, two families are immunized at the end of the second vaccination day. Now, suppose one of the not-immunized citizens gets the virus at the end of day two. It is easy to verify there will be an infected more in the family-based strategy (all the five components of the family) than in the random-based strategy (4 components because one of them was immunized before). Furthermore, this implies that there will be n additional dangerous external contacts in the family-based strategy than in the random-based strategy.
These observations make us conclude that a random vaccination strategy will slow down the infection dynamics in village A while it will speed up infections in village B, and the opposite is true for the family-based immunization strategy.
Some simulation exercises
In this part of the document, the model described above will be used to compare further the family-based and random-based vaccination strategy to be used against the appearance of a new case (or variant) in a situation similar to that described in the example but with a more realistic setting.
As one can easily imagine, the family size distribution and COVID transmission risk in families are crucial to our simulation exercises. It is therefore important to gather real-world information for these phenomena. Fortunately, recent scientific contributions can help.
Several authors point out that a Poisson distribution is a good statistical model representing the family size distribution. This distribution is suitable because a single parameter characterizes it, i.e., its average, but it has the drawback of having a positive probability for zero value. Recently, Jarosz (2020) confirms the Poisson distribution’s goodness for modeling family size and shows how shifting it by one unit would be a valid alternative to solve the zero family size problem.
Furthermore, average family sizes data can be easily found using, for example, the OECD family database (http://www.oecd.org/social/family/database.htm).
The current version of the database (updated on 06-12-2016) presents data for 2015 with some exceptions. It shows how the average size of families in OECD countries is 2.46, ranging from Mexico (3.93) to Sweden (1.8).
The result in Metlay et al. (2021) guides the choice of the infection in the family parameter. They provide evidence of an overall household infection risk of 10.1%
Simulation exercises consist in parameters sensitivity analysis with respect to the benchmark parameter set reported hereafter.
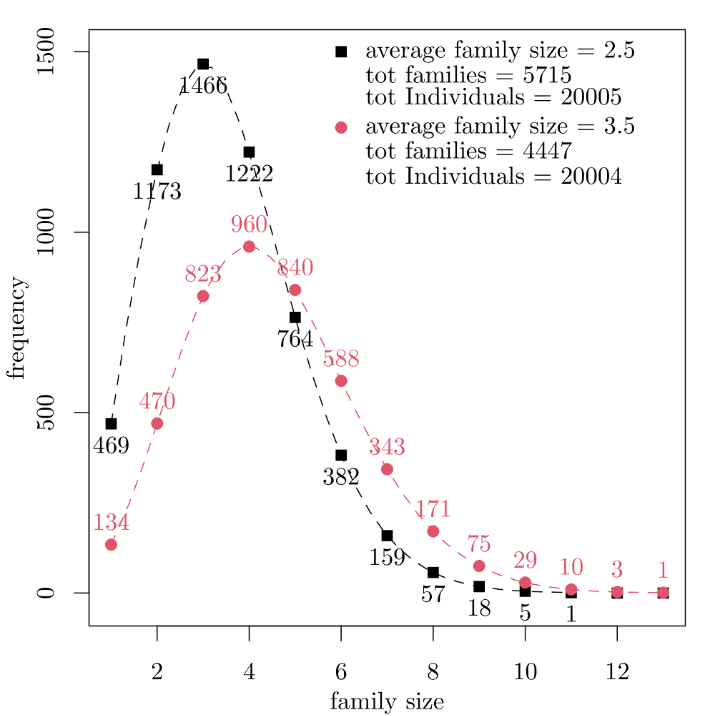
The simulation initialization is done by loading the family size distribution. Two alternative distributions are used and are tuned to obtain a system with a total number of individuals close to 20000. The two distributions are characterized by different average family sizes (afs) and are shown in figure 2.
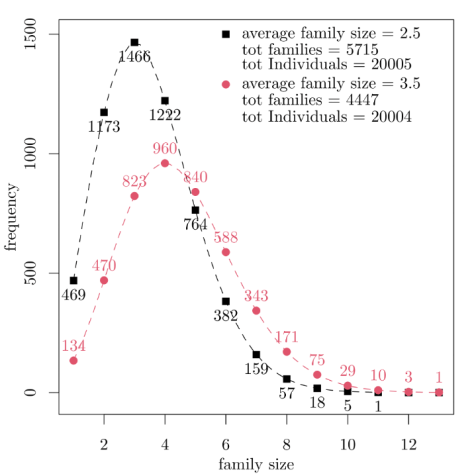
Figure 2: two family size distributions used to initialize the simulation. Figures by the dots inform on the frequency of the corresponding size. Black square relates to the distribution with an average of 2.5; red circles relate to the distribution with an average of 3.5
The description of the vaccination strategy gives a possibility to list other relevant parameters. The immunization center is endowed with nv doses of vaccine at each time starting from time tv. At time t0, the state of one of the individuals is changed from susceptible to infected. This subject (case zero) is taken from a family having three susceptibles among their components.
Case zero undergoes the same process as all other following infected individuals described above.
The relevant parameters of the simulations are reported in table 1.
| var |
description |
values |
reference |
| ni |
number of individuals |
≅20000 |
|
| afs |
average family size |
2.5;3.5 |
OECD |
| nv |
number of vaccine doses available at each time |
50;100;150 |
|
| tv |
vaccination starting time |
1 |
|
| t0 |
case zero appearance time |
10 |
|
| ll |
length of latency |
3 |
Buran et al 2021 |
| li |
length of infectious period |
5 |
Buran et al 2021 |
| pif |
probability to infect a family member |
0.1 |
Metlay et al 2021 |
| pof |
probability to infect a non-family individual |
0.01;0.02;0.03 |
|
| mof |
number of non-family contacts of an infectious |
10 |
|
Table 1: relevant parameters of the model.
We are now going to discuss the results of our simulation exercises. We focus particularly on the number of people infected up to a given point in time.
Due to the presence of random elements, each run has a different trajectory. We limit these effects as much as possible to allow ceteris paribus comparisons. For example, we keep the family size distribution equal across runs by loading the distributions displayed in figure 2 instead of using the run-time random number generator. Again, we set the number of non-family contacts (mof) equal for all the agents, although the code could set it randomly at each time step. Despite these randomness reductions, significant differences in the dynamics remain within the same parametrization because of randomness in the network of contacts.
To allow comparisons among different parametrizations in the presence of different evolution, we use the cross-section distributions of the total number of infected at the end of the infection process (i.e. time 200).
Figure 3 reports the empirical cumulative distribution function (ecdf) of several parametrizations. To easily read the figure, we put the different charts as in a plane having the average family size (afs) in the abscissa and the number of available vaccines (nv) in the ordinate. From above, we know two values of afs (i.e. 2.5 and 3.5) and three values of nv (i.e. 50, 100 and 150) are considered. Therefore figure 3 is made up of 6 charts.
Each chart reports ecdfs corresponding to the three different pof levels reported in table 1. In particular, circles denote edcfs for pof = 0.01, squares are for pof = 0.02 and triangles for pof = 0.03. At the end, choosing a parameters values triplet (afs, nv, pof), two ecdfs are identified. The red one is for the random-based, while the black one is for the family-based vaccination strategy. The family based vaccination strategy prioritizes families with higher number of members not yet infected.
Figure 3 shows mixed results: the random-based vaccination strategy outperforms the family-based one (the red line is above the balck one) for some parameters combinations while the reverse holds for others. In particular, the random-based tends to dominate the family-based strategy in case of larger family (afs = 3.5) and low and high vaccination levels (nv = 50 and 150). The opposite is true with smaller families at the same vaccination levels. The intermediate level of vaccination provides exceptions.
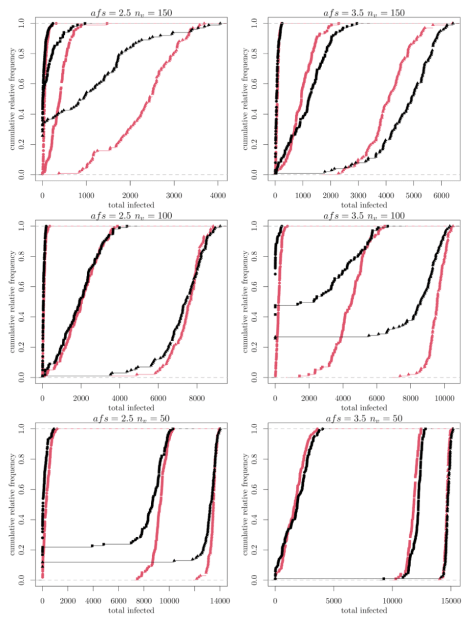
Figure 3: empirical cumulative distribution function of several parametrizations. The ecdfs is build by taking the number of infected people at period 200 of 100 runs with different random seed for each parametrization.
It is perhaps useful to highlight how, in the model, the family-based vaccination strategy stops the diffusion of a new wave or variant with a significant probability for smaller average family size and low and high vaccination levels (bottom-left and top-left charts) and for large average family size and middle level of vaccination (middle-right chart).
A conclusive note
At present, the model is very simple and can be improved in several directions. The most useful would probably be the inclusion of family-specific information. Setting up the model with additional information on each family member’s age or health state would allow overcoming the “universal mixing assumption” (Watts et al., 2020) currently in the model. Furthermore, additional vaccination strategy prioritization based on multiple criteria (such as vaccinating the families of most fragile or elderly) could be compared.
Initializing the model with census data of a local community could give a chance to analyze a more realistic setting in the wake of Pescarmona et al. (2020) and be more useful and understandable to (local) policy makers (Edmonds, 2020).
Developing the model to provide estimations for hospitalization and mortality is another needed step towards more sound vaccination strategies comparison.
Vaccinating by families could balance direct (vaccinating highest risk individuals) and indirect protection, i.e., limiting the probability the virus reaches most fragiles by vaccinating people with many contacts. It could also have positive economic effects relaunching, for example, family tourism. However, it cannot be implemented at risk of worsening the pandemic.
The present text aims only at posing a question. Further assessments following Squazzoni et al.’s (2020) recommendations are needed.
References
Barton, C.M. et al. (2020) Call for transparency of COVID-19 models. Science, 368(6490), 482-483. doi:10.1126/science.abb8637
Bubar, K.M. et al. (2021) Model-informed COVID-19 vaccine prioritization strategies by age and serostatus. Science 371, 916–921. doi:10.1126/science.abe6959
Edmonds, B. (2020) What more is needed for truly democratically accountable modelling? Review of Artificial Societies and Social Simulation, 2nd May 2020. https://rofasss.org/2020/05/02/democratically-accountable-modelling/
Jarosz, B. (2021) Poisson Distribution: A Model for Estimating Households by Household Size. Population Research and Policy Review, 40, 149–162. doi:10.1007/s11113-020-09575-x
Metlay J.P., Haas J.S., Soltoff A.E., Armstrong KA. Household Transmission of SARS-CoV-2. (2021) JAMA Netw Open, 4(2):e210304. doi:10.1001/jamanetworkopen.2021.0304
Pescarmona, G., Terna, P., Acquadro, A., Pescarmona, P., Russo, G., and Terna, S. (2020) How Can ABM Models Become Part of the Policy-Making Process in Times of Emergencies – The S.I.S.A.R. Epidemic Model. Review of Artificial Societies and Social Simulation, 20th Oct 2020. https://rofasss.org/2020/10/20/sisar/
Watts, C.J., Gilbert, N., Robertson, D., Droy, L.T., Ladley, D and Chattoe-Brown, E. (2020) The role of population scale in compartmental models of COVID-19 transmission. Review of Artificial Societies and Social Simulation, 14th August 2020. https://rofasss.org/2020/08/14/role-population-scale/
Squazzoni, F., Polhill, J. G., Edmonds, B., Ahrweiler, P., Antosz, P., Scholz, G., Chappin, É., Borit, M., Verhagen, H., Giardini, F. and Gilbert, N. (2020) Computational Models That Matter During a Global Pandemic Outbreak: A Call to Action. Journal of Artificial Societies and Social Simulation, 23(2):10. <http://jasss.soc.surrey.ac.uk/23/2/10.html>. doi: 10.18564/jasss.4298
Giulioni, G. (2020) Should the family size be used in COVID-19 vaccine prioritization strategy to prevent variants diffusion? A first investigation using a basic ABM. Review of Artificial Societies and Social Simulation, 15th April 2021. https://rofasss.org/2021/04/15/famsize/