Model Intercomparison
The recent Covid crisis has led to a surge of new model development and a renewed interest in the use of models as policy tools. While this is in some senses welcome, the sudden appearance of many new models presents a problem in terms of their assessment, the appropriateness of their application and reconciling any differences in outcome. Even if they appear similar, their underlying assumptions may differ, their initial data might not be the same, policy options may be applied in different ways, stochastic effects explored to a varying extent, and model outputs presented in any number of different forms. As a result, it can be unclear what aspects of variations in output between models are results of mechanistic, parameter or data differences. Any comparison between models is made tricky by differences in experimental design and selection of output measures.
If we wish to do better, we suggest that a more formal approach to making comparisons between models would be helpful. However, it appears that this is not commonly undertaken most fields in a systematic and persistent way, except for the field of climate change, and closely related fields such as pollution transport or economic impact modelling (although efforts are underway to extend such systematic comparison to ecosystem models – Wei et al., 2014, Tittensor et al., 2018). Examining the way in which this is done for climate models may therefore prove instructive.
Model Intercomparison Projects (MIP) in the Climate Community
Formal intercomparison of atmospheric models goes back at least to 1989 (Gates et al., 1999) with the first atmospheric model inter-comparison project (AMIP), initiated by the World Climate Research Programme. By 1999 this had contributions from all significant atmospheric modelling groups, providing standardised time-series of over 30 model variables for one particular historical decade of simulation, with a standard experimental setup. Comparisons of model mean values with available data helped to reveal overall model strengths and weaknesses: no single model was best at simulation of all aspects of the atmosphere, with accuracy varying greatly between simulations. The model outputs also formed a reference base for further inter-comparison experiments including targets for model improvement and reduction of systematic errors, as well as a starting point for improved experimental design, software and data management standards and protocols for communication and model intercomparison. This led to AMIPII and, subsequently, to a series of Climate model inter-comparison projects (CMIP) beginning with CMIP I in 1996. The latest iteration (CMIP 6) is a collection of 23 separate model intercomparison experiments covering atmosphere, ocean, land surface, geo-engineering, and the paleoclimate. This collection is aimed at the upcoming 2021 IPCC process (AR6). Participating projects go through an endorsement process for inclusion, (a process agreed with modelling groups), based on 10 criteria designed to ensure some degree of coherence between the various models – a further 18 MIPS are also listed as currently active (https://www.wcrp-climate.org/wgcm-cmip/wgcm-cmip6). Groups contribute to a central set of common experiments covering the period 1850 to the near-present. An overview of the whole process can be found in (Eyring et al., 2016).
The current structure includes a set of three overarching questions covering the dynamics of the earth system, model systematic biases and understanding possible future change under uncertainty. Individual MIPS may build on this to address one or more of a set of 7 “grand science challenges” associated with the climate. Modelling groups agree to provide outputs in a standard form, obtained from a specified set of experiments under the same design, and to provide standardised documentation to go with their models. Originally (up to CMIP 5), outputs were then added to a central public repository for further analysis, however the output grew so large under CMIP6 that now the data is held dispersed over repositories maintained by separate groups.
Other Examples
Two further more recent examples of collective model development may also be helpful to consider.
Firstly, an informal network collating models across more than 50 research groups has already been generated as a result of the COVID crisis – the Covid Forecast Hub (https://covid19forecasthub.org). This is run by a small number of research groups collaborating with the US Centre for Disease Control and is strongly focussed on the epidemiology. Participants are encouraged to submit weekly forecasts, and these are integrated into a data repository and can be vizualized on the website – viewers can look at forward projections, along with associated confidence intervals and model evaluation scores, including those for an ensemble of all models. The focus on forecasts in this case arises out of the strong policy drivers for the current crisis, but the main point is that it is possible to immediately view measures of model performance and to compare the different model types: one clear message that rapidly becomes apparent is that many of the forward projections have 95% (and at some times, even 50%) confidence intervals for incident deaths that more than span the full range of the past historic data. The benefit of comparing many different models in this case is apparent, as many of the historic single-model projections diverge strongly from the data (and the models most in error are not consistently the same ones over time), although the ensemble mean tends to be better.
As a second example, one could consider the Psychological Science Accelerator (PSA: Moshontz et al 2018, https://psysciacc.org/). This is a collaborative network set up with the aim of addressing the “replication crisis” in psychology: many previously published results in psychology have proved problematic to replicate as a result of small or non-representative sampling or use of experimental designs that do not generalize well or have not been used consistently either within or across studies. The PSA seeks to ensure accumulation of reliable and generalizable evidence in psychological science, based on principles of inclusion, decentralization, openness, transparency and rigour. The existence of this network has, for example, enabled the reinvestigation of previous experiments but with much larger and less nationally biased samples (e.g. Jones et al 2021).
The Benefits of the Intercomparison Exercises and Collaborative Model Building
More specifically, long-term intercomparison projects help to do the following.
- Build on past effort. Rather than modellers re-inventing the wheel (or building a new framework) with each new model project, libraries of well-tested and documented models, with data archives, including code and experimental design, would allow researchers to more efficiently work on new problems, building on previous coding effort
- Aid replication. Focussed long term intercomparison projects centred on model results with consistent standardised data formats would allow new versions of code to be quickly tested against historical archives to check whether expected results could be recovered and where differences might arise, particularly if different modelling languages were being used
- Help to formalize. While informal code archives can help to illustrate the methods or theoretical foundations of a model, intercomparison projects help to understand which kinds of formal model might be good for particular applications, and which can be expected to produce helpful results for given desired output measures
- Build credibility. A continuously updated set of model implementations and assessment of their areas of competence and lack thereof (as compared with available datasets) would help to demonstrate the usefulness (or otherwise) of ABM as a way to represent social systems
- Influence Policy (where appropriate). Formal international policy organisations such as the IPCC or the more recently formed IPBES are effective partly through an underpinning of well tested and consistently updated models. As yet it is difficult to see whether such a body would be appropriate or effective for social systems, as we lack the background of demonstrable accumulated and well tested model results.
Lessons for ABM?
What might we be able to learn from the above, if we attempted to use a similar process to compare ABM policy models?
In the first place, the projects started small and grew over time: it would not be necessary, for example, to cover all possible ABM applications at the outset. On the other hand, the latest CMIP iterations include a wide range of different types of model covering many different aspects of the earth system, so that the breadth of possible model types need not be seen as a barrier.
Secondly, the climate inter-comparison project has been persistent for some 30 years – over this time many models have come and gone, but the history of inter-comparisons allows for an overview of how well these models have performed over time – data from the original AMIP I models is still available on request, supporting assessments concerning long-term model improvement.
Thirdly, although climate models are complex – implementing a variety of different mechanisms in different ways – they can still be compared by use of standardised outputs, and at least some (although not necessarily all) have been capable of direct comparison with empirical data.
Finally, an agreed experimental design and public archive for documentation and output that is stable over time is needed; this needs to be done via a collective agreement among the modelling groups involved so as to ensure a long-term buy-in from the community as a whole, so that there is a consistent basis for long-term model development, building on past experience.
The need for aligning or reproducing ABMs has long been recognised within the community (Axtell et al. 1996; Edmonds & Hales 2003), but on a one-one basis for verifying the specification of models against their implementation, although (Hales et al. 2003) discusses a range of possibilities. However, this is far from a situation where many different models of basically the same phenomena are systematically compared – this would be a larger scale collaboration lasting over a longer time span.
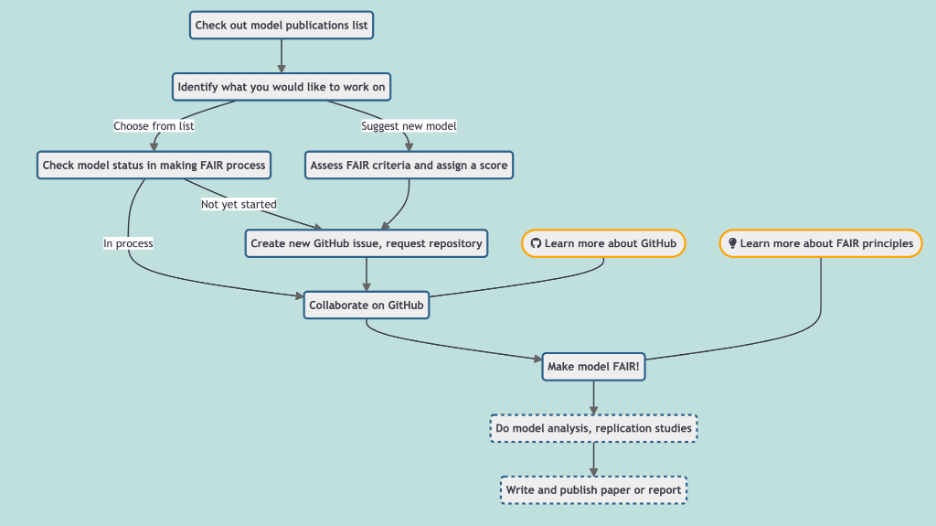
The community has already established a standardised form of documentation in the ODD protocol. Sharing of model code is also becoming routine, and can be easily achieved through COMSES, Github or similar. The sharing of data in a long-term archive may require more investigation. As a starting project COVID-19 provides an ideal opportunity for setting up such a model inter-comparison project – multiple groups already have running examples, and a shared set of outputs and experiments should be straightforward to agree on. This would potentially form a basis for forward looking experiments designed to assist with possible future pandemic problems, and a basis on which to build further features into the existing disease-focussed modelling, such as the effects of economic, social and psychological issues.
Additional Challenges for ABMs of Social Phenomena
Nobody supposes that modelling social phenomena is going to have the same set of challenges that climate change models face. Some of the differences include:
- The availability of good data. Social science is bedevilled by a paucity of the right kind of data. Although an increasing amount of relevant data is being produced, there are commercial, ethical and data protection barriers to accessing it and the data rarely concerns the same set of actors or events.
- The understanding of micro-level behaviour. Whilst the micro-level understanding of our atmosphere is very well established, those of the behaviour of the most important actors (humans) is not. However, it may be that better data might partially substitute for a generic behavioural model of decision-making.
- Agreement upon the goals of modelling. Although there will always be considerable variation in terms of what is wanted from a model of any particular social phenomena, a common core of agreed objectives will help focus any comparison and give confidence via ensembles of projections. Although the MIPs and Covid Forecast Hub are focussed on prediction, it may be that empirical explanation may be more important in other areas.
- The available resources. ABM projects tend to be add-ons to larger endeavours and based around short-term grant funding. The funding for big ABM projects is yet to be established, not having the equivalent of weather forecasting to piggy-back on.
- Persistence of modelling teams/projects. ABM tends to be quite short-term with each project developing a new model for a new project. This has made it hard to keep good modelling teams together.
- Deep uncertainty. Whilst the set of possible factors and processes involved in a climate change model are well established, which social mechanisms need to be involved in any model of any particular social phenomena is unknown. For this reason, there is deep disagreement about the assumptions to be made in such models, as well as sharp divergence in outcome due to changes brought about by a particular mechanism but not included in a model. Whilst uncertainty in known mechanisms can be quantified, assessing the impact of those due to such deep uncertainty is much harder.
- The sensitivity of the political context. Even in the case of Climate Change, where the assumptions made are relatively well understood and done on objective bases, the modelling exercise and its outcomes can be politically contested. In other areas, where the representation of people’s behaviour might be key to model outcomes, this will need even more care (Adoha & Edmonds 2017).
However, some of these problems were solved in the case of Climate Change as a result of the CMIP exercises and the reports they ultimately resulted in. Over time the development of the models also allowed for a broadening and updating of modelling goals, starting from a relatively narrow initial set of experiments. Ensuring the persistence of individual modelling teams is easier in the context of an internationally recognised comparison project, because resources may be easier to obtain, and there is a consistent central focus. The modelling projects became longer-term as individual researchers could establish a career doing just climate change modelling and importance of the work increasingly recognised. An ABM modelling comparison project might help solve some of these problems as the importance of its work is established.
Towards an Initial Proposal
The topic chosen for this project should be something where there: (a) is enough public interest to justify the effort, (b) there are a number of models with a similar purpose in mind being developed. At the current stage, this suggests dynamic models of COVID spread, but there are other possibilities, including: transport models (where people go and who they meet) or criminological models (where and when crimes happen).
Whichever ensemble of models is focussed upon, these models should be compared on a core of standard, with the same:
- Start and end dates (but not necessarily the same temporal granularity)
- Covering the same set of regions or cases
- Using the same population data (though possibly enhanced with extra data and maybe scaled population sizes)
- With the same initial conditions in terms of the population
- Outputting a core of agreed measures (but maybe others as well)
- Checked against their agreement against a core set of cases, with agreed data sets
- Reported on in a standard format (though with a discussion section for further/other observations)
- well documented and with code that is open access
- Run a minimum of times with different random seeds
Any modeller/team that had a suitable model and was willing to adhere to the rules would be welcome to participate (commercial, government or academic) and these teams would collectively decide the rules, development and write any reports on the comparisons. Other interested stakeholder groups could be involved including professional/academic associations, NGOs and government departments but in a consultative role providing wider critique – it is important that the terms and reports from the exercise be independent or any particular interest or authority.
Conclusion
We call upon those who think ABMs have the potential to usefully inform policy decisions to work together, in order that the transparency and rigour of our modelling matches our ambition. Whilst model comparison exercises of the kind described are important for any simulation work, particular care needs to be taken when the outcomes can affect people’s lives.
References
Aodha, L. & Edmonds, B. (2017) Some pitfalls to beware when applying models to issues of policy relevance. In Edmonds, B. & Meyer, R. (eds.) Simulating Social Complexity – a handbook, 2nd edition. Springer, 801-822. (A version is at http://cfpm.org/discussionpapers/236)
Axtell, R., Axelrod, R., Epstein, J. M., & Cohen, M. D. (1996). Aligning simulation models: A case study and results. Computational & Mathematical Organization Theory, 1(2), 123-141. https://link.springer.com/article/10.1007%2FBF01299065
Edmonds, B., & Hales, D. (2003). Replication, replication and replication: Some hard lessons from model alignment. Journal of Artificial Societies and Social Simulation, 6(4), 11. http://jasss.soc.surrey.ac.uk/6/4/11.html
Eyring, V., Bony, S., Meehl, G. A., Senior, C. A., Stevens, B., Stouffer, R. J., & Taylor, K. E. (2016). Overview of the Coupled Model Intercomparison Project Phase 6 (CMIP6) experimental design and organization. Geoscientific Model Development, 9(5), 1937–1958. https://doi.org/10.5194/gmd-9-1937-2016
Gates, W. L., Boyle, J. S., Covey, C., Dease, C. G., Doutriaux, C. M., Drach, R. S., Fiorino, M., Gleckler, P. J., Hnilo, J. J., Marlais, S. M., Phillips, T. J., Potter, G. L., Santer, B. D., Sperber, K. R., Taylor, K. E., & Williams, D. N. (1999). An Overview of the Results of the Atmospheric Model Intercomparison Project (AMIP I). In Bulletin of the American Meteorological Society (Vol. 80, Issue 1, pp. 29–55). American Meteorological Society. https://doi.org/10.1175/1520-0477(1999)080<0029:AOOTRO>2.0.CO;2
Hales, D., Rouchier, J., & Edmonds, B. (2003). Model-to-model analysis. Journal of Artificial Societies and Social Simulation, 6(4), 5. http://jasss.soc.surrey.ac.uk/6/4/5.html
Jones, B.C., DeBruine, L.M., Flake, J.K. et al. To which world regions does the valence–dominance model of social perception apply?. Nat Hum Behav 5, 159–169 (2021). https://doi.org/10.1038/s41562-020-01007-2
Moshontz, H. + 85 others (2018) The Psychological Science Accelerator: Advancing Psychology Through a Distributed Collaborative Network , 1(4) 501-515. https://doi.org/10.1177/2515245918797607
Tittensor, D. P., Eddy, T. D., Lotze, H. K., Galbraith, E. D., Cheung, W., Barange, M., Blanchard, J. L., Bopp, L., Bryndum-Buchholz, A., Büchner, M., Bulman, C., Carozza, D. A., Christensen, V., Coll, M., Dunne, J. P., Fernandes, J. A., Fulton, E. A., Hobday, A. J., Huber, V., … Walker, N. D. (2018). A protocol for the intercomparison of marine fishery and ecosystem models: Fish-MIP v1.0. Geoscientific Model Development, 11(4), 1421–1442. https://doi.org/10.5194/gmd-11-1421-2018
Wei, Y., Liu, S., Huntzinger, D. N., Michalak, A. M., Viovy, N., Post, W. M., Schwalm, C. R., Schaefer, K., Jacobson, A. R., Lu, C., Tian, H., Ricciuto, D. M., Cook, R. B., Mao, J., & Shi, X. (2014). The north american carbon program multi-scale synthesis and terrestrial model intercomparison project – Part 2: Environmental driver data. Geoscientific Model Development, 7(6), 2875–2893. https://doi.org/10.5194/gmd-7-2875-2014
Bithell, M. and Edmonds, B. (2020) The Systematic Comparison of Agent-Based Policy Models - It’s time we got our act together!. Review of Artificial Societies and Social Simulation, 11th May 2021. https://rofasss.org/2021/05/11/SystComp/