Reproducing simulation models is essential for verifying them and critiquing them. This involves a lot more work than one would think (Axtell & al. 1996) and can reveal surprising flaws, even in the simplest of models (e.g. Edmonds & Hales 2003). Such reproduction is especially vital if the model outcomes are likely to affect people’s lives (Chattoe-Brown & al. 2021).
Whilst substantial pieces of work – where there is extensive analysis or extension – can be submitted to JASSS/CMOT, some such reports might be much simpler and not justify a full journal paper. Thus RofASSS has decided to encourage researchers to submit reports of reproductions here – however simple or complicated.
Similarly, JASSS, CMOT etc. do publish book reviews, but these tend to be of recent books. Although new books are of obvious interest to those at the cutting edge of research, it often happens that important papers & books are forgotten or overlooked. At RofASSS we would like to encourage reviews of any relevant book or paper, however old.
References
Axtell, R., Axelrod, R., Epstein, J. M., & Cohen, M. D. (1996). Aligning simulation models: A case study and results. Computational & Mathematical Organization Theory, 1, 123-141. DOI: 10.1007/BF01299065
Edmonds, B., & Hales, D. (2003). Replication, replication and replication: Some hard lessons from model alignment. Journal of Artificial Societies and Social Simulation, 6(4), 11. https://jasss.soc.surrey.ac.uk/6/4/11.html
Chattoe-Brown, E. Gilbert, N., Robertson, D. A. & Watts, C. (2021) Reproduction as a Means of Evaluating Policy Models: A Case Study of a COVID-19 Simulation. medRxiv 2021.01.29.21250743; DOI: 10.1101/2021.01.29.21250743
Information and Computational Sciences Department, The James Hutton Institute, Aberdeen AB15 8QH, UK.
High-performance computing (HPC) clusters are increasingly being used for agent-based modelling (ABM) studies. There are reasons why HPC provides a significant benefit for ABM work, and to expect a growth in HPC/ABM applications:
ABMs typically feature stochasticity, which require multiple runs using the same parameter settings and initial conditions to ascertain the scope of the behaviour of the model. The ODD protocol has stipulated the explicit specification of this since it was first conceived (Grimm et al. 2006). Some regard stochasticity as ‘inelegant’ and to be avoided in models, but asynchrony in agents’ actions can avoid artefacts (results being a ‘special case’ rather than a ‘typical case’) and introduces an extra level of complexity affecting the predictability of the system even when all data are known (Polhill et al. 2021).
ABMs often have high-dimensional parameter spaces, which need to be sampled for sensitivity analyses and, in the case of empirical ABMs, for calibration and validation. The so-called ‘curse of dimensionality’ means that the problem of exploring parameter space grows exponentially with the number of parameters. While ABMs’ parameters may not all be ‘orthogonal’ (i.e. each point in parameter space does not uniquely specify model behaviour – a situation sometimes referred to as ‘equifinality’), diminishing the ‘curse’, the exponential growth means the challenge of parameter search does not need many dimensions before it becomes intractable exhaustively.
Both the above points are exacerbated in empirical applications of ABMs given Sun et al.’s (2016) observations about the ‘medawar zone’ of model complicatedness in relation to that of theoretical models. In empirical applications, we also may be more interested in knowing that an undesirable outcome cannot occur, or has a very low probability of occurring, requiring more runs with the same conditions. Further, the additional complicatedness of empirical ABM will entail more parameters, and the empirical application will place greater emphasis on searching parameter space for calibrating and validating to data.
HPC clusters are shared computing resources, and it is now commonplace for research organizations and universities to have them. There can be few academic disciplines without some sort of scientific computing requirement – typical applications include particle physics, astronomy, meteorology, materials, chemistry, neuroscience, medicine and genetics. And social science. As a shared resource, an HPC cluster is subject to norms and institutions frequently observed in common-pool resource dilemmas. Users of HPC clusters are asked to request allocations of computing time, memory and long-term storage space to accommodate their needs. The requests are made in advance of the runs being executed; sometimes so far in advance that the calculations form part of the research project proposal. Hence, as a user, if you do not know, or cannot calculate, the resources you will require, you have a dilemma: ask for more than it turns out you really need and risk normative sanctions; or ask for less than it turns out you really need and impair the scientific quality of your research. Normative sanctions are in the job description of the HPC cluster administrator. This can lead to emails such as those in Figure 1.
Figure 1: Example email and accompanying visualization from an HPC cluster administrator reminding users that it is antisocial to request more resources than you will use when submitting jobs.
The ‘managerialist’ turn in academia has been lamented in various articles. Kolsaker (2008), while presenting a nuanced view of the relationship between managerialist and academic modes of working, says that “managerialism represents a distinctive discourse based upon a set of values that justify the assumed right of one group to monitor and control the activities of others.” Steinþórsdóttir et al. (2019) note in the abstract to their article that their results from a case study in Iceland support arguments that managerialism discriminates against women and early-career researchers, in part because of a systemic bias towards natural sciences. Both observations are relevant in this context.
Measurement and control as the tools of managerialist conduct renders Goodhart’s Law (the principle that when a metric becomes a target, the metric is useless) relevant. Goodhart’s Law has been found to have led to bibliometrics now being useless for comparing researchers’ performance – both within and between departments (Fire and Guestrin 2019). We may therefore expect that if an HPC cluster’s administrator has the accurate prediction of computing resource as a target for their own performance assessment, or if they give it as a target for users – e.g. by prioritizing jobs submitted by users on the basis of the accuracy of their predicted resource use, or denying access to those consistently over-estimating requirements – this accuracy will be useless. To give a concrete example, programming languages such as C give the programmer direct control over memory allocation. Hence, were access to an HPC conditional on the accurate prediction of memory allocation requirements, a savvy C programmer would have the (excessive) memory allowance in the batch job submission as a command-line argument to their program, which on execution would immediately request that allocation from the server’s operating system. The rest of the program would use bespoke memory allocation functions that allocated the memory the program actually needed from the memory initially reserved. Similar principles can be used for CPU cycles – if the program runs too quickly, then calculate digits of π until the predicted CPU time has elapsed; and disk space – if too much disk space has been requested, then pad files with random data. These activities waste the programmer’s time, and entail additional use of computing resources with energy cost implications for the cluster administrator.
With respect to the normative statements such as those in Figure 1, Griesemer (2020, p. 77), discussing the use of metrics leading to ‘gaming the system’ in academia generally (the savvy C programmer’s behaviour being an example in the context of HPC usage) claims that “it is … problematic to moralize and shame [such] practices as if it were clear what constitutes ethical … practice in social worlds where Goodhart’s law operates” [emphasis mine]. In computer science, however, there are theoretical (in the mathematical sense of the term) reasons why such norms are problematic over-and-above the social context of measurement-and-control.
The theory of computer science is founded in mathematics and logic, and the work of notable thinkers such as Gödel, Turing, Hilbert, Kolmogorov, Chomsky, Shannon, Tarski, Russell and von Neumann. The growth in areas of computer science (e.g. artificial intelligence, internet-of-things) means that undergraduate degrees have increasingly less space to devote to teaching this theory. Blumenthal (2021, p. 46), comparing computer science curricula in 2014 and 2021, found that the proportion of courses with required modules on computational theory had dropped from 46% to 40%, though the sample size meant this result was not significant (P = 0.09 under a two-population z-test). Similarly, the time dedicated to algorithmics and complexity in CS2013 fell to 28 (of which 19 are ‘tier-1’ – required of every curriculum; and 9 are ‘tier-2’ – in which 80% topic coverage is the stipulated minimum) from 31 in CS2008 (Joint Task Force on Computing Curricula 2013).
One of the most critical theoretical results in computer science is the so-called Halting Problem (Turing 1937), which proves that it is impossible to write a computer program that (in the general case) takes as input another computer program and its input data and gives as output whether the latter program will halt or run forever. The halting problem is ‘tier-1’ in CS2013, and so should be taught to every computer scientist. Rice (1953) generalized Turing’s finding to prove that any ‘non-trivial’ properties of computer programs could not be decided algorithmically. These results mean that the automated job scheduling and resource allocation algorithms in HPC, such as SLURM (Yoo et al. 2003), cannot take a user’s submitted job as input and calculate the computing resources it will need. Any requirement for such prediction is thus pushed to the user. In the general case, this means users of HPC clusters are being asked to solve formally undecidable problems when submitting jobs. Qualified computer scientists should know this – but possibly not all cluster administrators, and certainly not all cluster users, are qualified computer scientists. The power dynamic implied by Kolsaker’s (2008) characterization of a managerialist working culture puts users as a disadvantage, while Steinþórsdóttir et al.’s (2019) observations suggest this practice may be indirectly discriminatory on the basis of age and gender; the latter particularly when social scientists are seeking access to shared HPC facilities.
I emphasized ‘in the general case’ above because in many specific cases, computing resources can be accurately estimated. Sorting a list of strings in alphabetical order, for example is known to grow in execution time with as a function of n log n, where n is the length of the list. Integers can even be sorted in linear time, but with demands on memory that are exponential in the number of bits used to store an integer (Andersson et al. 1998).
However, agent-based modellers should not expect to be so lucky. There are various features that ABMs may implement that make their computing resources difficult (perhaps impossible) to predict:
Birth and death of agents can render computing time and memory requirements difficult to predict. Indeed, the size of the population and any fluctuation in it may be the purpose of the simulation study. With each agent having memory needed to store its attributes, and execution time for its behaviour, if the maximum population size of a specific run is not predictable from its initial conditions and parameter settings without first running the model, then computing resources cannot be predicted for HPC job submission.
A more dramatic corollary of birth and death is the question of extinction – i.e. where all agents die before they can reproduce. At this point, a run would typically terminate – far sooner than the computing time budgeted.
Interactions among agents, where the set of other agents with which one agent interacts is not predetermined, will also typically result in unpredictable computing times, even if the time needed for any one interaction is known. In some cases, agents’ social networks may be formally represented using data structures (‘links’ in NetLogo), and if these connections can be created or destroyed as a result of the model’s dynamics, then the memory requirements will typically be unpredictable.
Memories of agents, where implemented, are most trivially stored in lists that may have arbitrary length. The algorithms implementing the agents’ behaviours that use their memories will have computing times that are a function of the list length at any one time. These lists may not have a predictable length (e.g. if the agent ‘forgets’ some memories) and hence their behavioural algorithms won’t have predictable execution time.
Gotts and Polhill (2010) have shown that running a specific model with larger spaces led to qualitatively different results than with smaller spaces. This suggests that smaller (personal) computers (such as desktops and laptops) cannot necessarily be used to accurately estimate execution times and memory requirements prior to submitting larger-scale simulations requiring resources only available on HPC clusters.
Worse, a job will typically comprise several runs in a ‘batch’ covering multiple parameter settings and/or initial conditions. Even if the maximum time and memory requirements of any of the runs in a batch were known, there is no guarantee that all of the other runs will use anything like as much. These matters combine to make agent-based modellers ‘antisocial’ users of HPC clusters where the ‘performance’ of the clusters’ users is measured by their ability to accurately predict resource requirements, or there isn’t an ‘accommodating’ relationship between the administrator and researcher. Further, the social environment in which researchers access these resources put early-career and female researchers at a potential systemic disadvantage
The main purpose of making these points is to lay down the foundations for more equitable access to HPC for social scientists, and provide tentative users of these facilities with the arguments they need to develop constructive working arrangements with cluster administrators for them to run their agent-based models on shared HPC equipment.
Acknowledgements
This work was supported by the Scottish Government Rural and Environment Science and Analytical Services Division (project reference JHI-C5-1)
References
Andersson, A., Hagerup, T., Nilsson, S. and Raman, R. (1998) Sorting in linear time? Journal of Computer and System Sciences57, 74-93. https://doi.org/10.1006/jcss.1998.1580
Blumenthal, R. (2021) Walking the curricular talk: a longitudinal study of computer science departmental course requirements. In Lu, B. and Smallwood, P. (eds.) The Journal of Computing Sciences in Colleges: Papers of the 30th Annual CCSC Rocky Mountain Conference, October 15th-16th, 2021, Utah Valley University (virtual), Orem, UT. Volume 37, Number 2, pp. 40-50.
Fire, M. and Guestrin, C. (2019) Over-optimization of academic publishing metrics: observing Goodhart’s Law in action. GigaScience8 (6), giz053. https://doi.org/10.1093/gigascience/giz053
Gotts, N. M. and Polhill, J. G. (2010) Size matters: large-scale replications of experiments with FEARLUS. Advances in Complex Systems13 (4), 453-467. https://doi.org/10.1142/S0219525910002670
Griesemer, J. (2020) Taking Goodhart’s Law meta: gaming, meta-gaming, and hacking academic performance metrics. In Kippmann, A. and Biagioli, M. (eds.) Gaming the Metrics: Misconduct and Manipulation in Academic Research. Cambridge, MA, USA: The MIT Press, pp. 77-87.
Grimm, V., Berger, U., Bastiansen, F., Eliassen, S., Ginot, V., Giske, J., Goss-Custard, J., Grand, T., Heinz, S. K., Huse, G., Huth, A., Jepsen, J. U., Jørgensen, C., Mooij, W. M., Müller, B., Pe’er, G., Piou, C., Railsback, S. F., Robbins, A. M., Robbins, M. M., Rossmanith, E., Rüger, N., Strand, E., Souissi, S., Stillman, R. A., Vabø, R., Visser, U. and DeAngelis, D. L. (2006) A standard protocol for describing individual-based and agent-based models. Ecological Modelling198, 115-126. https://doi.org/10.1016/j.ecolmodel.2006.04.023
(The) Joint Task Force on Computing Curricula, Association for Computing Machinery (ACM) IEEE Computer Society (2013) Computer Science Curricula 2013: Curriculum Guidelines for Undergraduate Degree Programs in Computer Science. https://doi.org/10.1145/2534860
Kolsaker, A. (2008) Academic professionalism in the managerialist era: a study of English universities. Studies in Higher Education33 (5), 513-525. https://doi.org/10.1080/03075070802372885
Polhill, J. G., Hare, M., Bauermann, T., Anzola, D., Palmer, E., Salt, D. and Antosz, P. (2021) Using agent-based models for prediction in complex and wicked systems. Journal of Artificial Societies and Social Simulation24 (3), 2. https://doi.org/10.18564/jasss.4597
Rice, H. G. (1953) Classes of recursively enumerable sets and their decision problems. Transactions of the American Mathematical Society74, 358-366. https://doi.org/10.1090/S0002-9947-1953-0053041-6
Steinþórsdóttir, F. S., Brorsen Smidt, T., Pétursdóttir, G. M., Einarsdóttir, Þ, and Le Feuvre, N. (2019) New managerialism in the academy: gender bias and precarity. Gender, Work & Organization26 (2), 124-139. https://doi.org/10.1111/gwao.12286
Sun, Z., Lorscheid, I., Millington, J. D., Lauf, S., Magliocca, N. R., Groeneveld, J., Balbi, S., Nolzen, H., Müller, B., Schulze, J. and Buchmann, C. M. (2016) Simple or complicated agent-based models? A complicated issue. Environmental Modelling & Software86, 56-67. https://doi.org/10.1016/j.envsoft.2016.09.006
Turing, A. M. (1937) On computable numbers, with an application to the Entscheidungsproblem. Proceedings of the London Mathematical Societys2-42 (1), 230-265. https://doi.org/10.1112/plms/s2-42.1.230
Yoo, A. B., Jette, M. A. and Grondona, M. (2003) SLURM: Simple Linux utility for resource management. In Feitelson, D., Rudolph, L. and Schwiegelshohn, U. (eds.) Job Scheduling Strategies for Parallel Processing. 9th International Workshop, JSSPP 2003, Seattle, WA, USA, June 2003, Revised Papers. Lecture Notes in Computer Science2862, pp. 44-60. Berlin, Germany: Springer. https://doi.org/10.1007/10968987_3
Polhill, G. (2022) Antisocial simulation: using shared high-performance computing clusters to run agent-based models. Review of Artificial Societies and Social Simulation, 14 Dec 2022. https://rofasss.org/2022/12/14/antisoc-sim
By Nanda Wijermans, Geeske Scholz, Rocco Paolillo, Tobias Schröder, Emile Chappin, Tony Craig, and Anne Templeton
Introduction
Understanding how individual or group behaviour are influenced by the presence of others is something both social psychology and agent-based social simulation are concerned with. However, there is only limited overlap between these two research communities, which becomes clear when terms such as “variable”, “prediction”, or “model” come into play, and we build on their different meanings. This situation challenges us when working together, since it complicates the uptake of relevant work from each community and thus hampers the potential impact that we could have when joining forces.
We[1] – a group of social psychologists and social simulation modellers – sought to clarify the meaning of models and modelling from an interdisciplinary perspective involving these two communities. This occurred while starting our collaboration to formalise ‘social identity approaches’ (SIA). It was part of our journey to learn how to communicate and understand each other’s work, insights, and arguments during our discussions.
We present a summary of our reflections on what we learned from and with each other in this paper, which we intend to be part of a conversation, complementary to existing readings on ABM and social psychology (e.g., Lorenz, Neumann, & Schröder, 2021; Smaldino, 2020; Smith & Conrey, 2007). Complementary, because one comes to understand things differently when engaging directly in conversation with people from other communities, and we hope to extend this from our network to the wider social simulation community.
What are variable- and agent-based models?
We started the discussion by describing to each other what we mean when we talk about “a model” and distinguishing between models in the two communities as variable-based models in social psychology and agent-based modelling in social simulation.
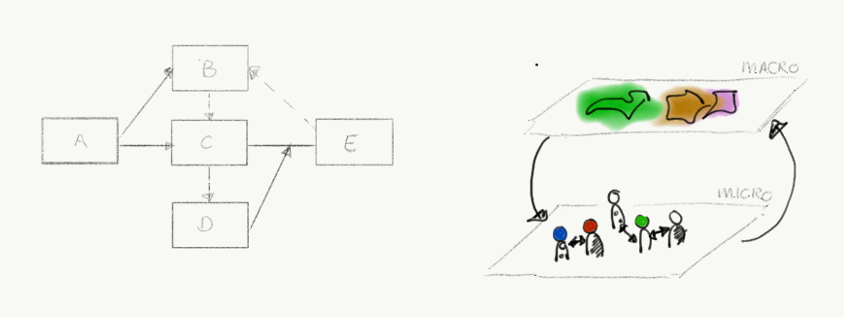
Models in social psychology generally come in two interrelated variants. Theoretical models, usually stated verbally and typically visualised with box-and-arrow diagrams as in Figure 1 (left), reflect assumptions of causal (but also correlational) relations between a limited number of variables. Statistical models are often based in theory and fitted to empirical data to test how well the explanatory variables predict the dependent variables, following the causal assumptions of the corresponding theoretical model. We therefore refer to social-psychological models as variable-based models (VBM). Core concepts are prediction and effect size. A prediction formulates whether one variable or combination of more variables causes an effect on an outcome variable. The effect size is the result of testing a prediction by indicating the strength of that effect, usually in statistical terms, the magnitude of variance explained by a statistical model.
It is good to realise that many social psychologists strive for a methodological gold standard using controlled behavioural experiments. Ideally, one predicts data patterns based on a theoretical model, which is then tested with data. However, observations of the real world are often messier. Inductive post hoc explanations emerge when empirical findings are unexpected or inconclusive. The discovery that much experimental work is not replicable has led to substantial efforts to increase the rigour of the methods, e.g., through the preregistration of experiments (Eberlen, Scholz & Gagliolo, 2017).
Models in Social Simulation come in different forms – agent-based models, mathematical models, microsimulations, system dynamic models etc – however here we focus on agent-based modelling as it is the dominant modelling approach within our SIAM network. Agent-based models reflect heterogeneous and autonomous entities (agents) that interact with each other and their environments over time (Conte & Paolucci, 2014; Gilbert & Troitzsch, 2005). Relationships between variables in ABMs need to be stated formally (equations or logical statements) in order to implement theoretical/empirical assumptions in a way that is understandable by a computer. An agent-based model can reflect assumptions about causal relations between as many variables as the modeller (team) intends to represent. Agent-based models are often used to help understand[2]why and how observed (macro) patterns arise by investigating the (micro/meso) processes underlying them (see Fig 1, right).
The extent to which social simulation models relate to data ranges from ‘no data used whatsoever’ to ‘fitting every variable value’ to empirical data. Put differently, the way one uses data does not define the approach. Note that assumptions based on theory and/or empirical observations do not suffice but require additional assumptions to make the model run.
Fig. 1: Visualisation of what a variable-based model in social psychology is (left) and what an agent-based model in social simulation is (right).
Comparing models
The discussion then moved from describing the meaning of “a model” to comparing similarities and differences between the concepts and approaches, but also what seems similar but is not…
Similar. The core commonalities of models in social psychology (VBM) and agent-based social simulation (ABM) are 1) the use of models to specify, test and/or explore (causal) relations between variables and 2) the ability to perform systematic experiments, surveys, or observations for testing the model against the real world. This means that words like ‘experimental design’, ‘dependent, independent and control variables’ have the same meaning. At the same time some aspects that are similar are labelled differently. For instance, the effect size in VBMs reflects the magnitude of the effect one can observe. In ABMs the analogy would be the sensitivity analysis, where one tests for the importance or role of certain variables on the emerging patterns in the simulation outcomes.
False Friends. There are several concepts that are given similar labels, but have different meanings. These are particularly important to be aware of in interdisciplinary settings as they can present “false friends”. The false friends we unpacked in our conversations are the following:
Model: whether the model is variable-based in social psychology (VBM) or agent-based in social simulation (ABM). The VBM focuses on the relation between two or a few variables typically in one snapshot of time, whereas the ABM focuses on the causal relations (mechanisms/processes) between (entities (agents) containing a number of) variables and simulates the resulting interactions over time.
Prediction: in VBMs a prediction is a variable-level claim, stating the expected magnitude of a relation between two or few variables. In ABMs prediction would instead be a claim about the future real-world system-level developments on the basis of observed phenomena in the simulation outcomes. In case such prediction is not the model purpose (which is likely), each future simulated system state is sometimes labelled nevertheless as a prediction, though it doesn’t mean to be necessarily accurate as a prediction to the real-world future. Instead, it can for example be a full explanation of the mechanisms required to replicate the particular phenomenon or a possible trajectory of which reality is just one.
Variable: here both types of models have variables (a label of some ‘thing’ that can have a certain ‘value’). In ABMs there can be many variables, some that have the same function as the variables in VBM (i.e., denoting a core concept and its value). Additionally, ABMs also have (many) variables to make things work.
Effect size: in VBM the magnitude of how much the independent variable can explain a dependent variable. In ABM the analogy would be sensitivity analysis, to determine the extent to which simulation outcomes are sensitive to changes in input settings. Note that, while effect size is critical in VBMs, in ABMs small effect sizes in micro interactions can lead toward large effects on the macro level.
Testing: VBMs usually test models using some form of hypothesis testing, whereas ABMs can be tested in very different ways (see David et al (2019)), depending on the purpose they have (e.g., explanation, theoretical exposition, prediction, see Edmonds et al. (2019)), and on different levels. For instance, testing can relate to the verification of the implementation of the model (software development specific), to make sure the model behaves as designed. However, testing can also relate to validation – checking whether the model lives up to its purpose – for instance testing the results produced by the ABM against real data if the aim is prediction of the real world-state.
Internal validity: in VBM this is to assure the causal relation between variables and their effect size. In ABMs it refers to the plausibility in assumptions and causal relations used in the model (design), e.g., by basing these on expert knowledge, empirical insights, or theory rather than on the modeller’s intuition only.
Differences. There are several differences when it comes to VBM and ABM. Firstly, there is a difference in what a model should replicate, i.e., the target of the model: in social psychology the focus tends to be on the relations between variables underlying behaviour, whereas in ABM it is usually on the macro-level patterns/structures that emerge. Also, the concept of causality differs in psychology, VBM models are predominantly built under the assumption of linear causality[3], with statistical models aiming to quantify the change in the dependent variable due to (associated) change in the independent variable. A causality or correlation often derived with “snapshot data”, i.e., one moment in time and one level of analysis. In ABMs, on the other hand, causality appears as a chain of causal relations that occur over time. Moreover, it can be non-linear (including multicausality, nonlinearity, feedback loops and/or amplifications of models’ outcomes). Lastly, the underlying philosophy can differ tremendously concerning the number of variables that are taken into consideration. By design, in social psychology one seeks to isolate the effects of variables, maintaining a high level of control to be confident about the effect of independent variables or the associations between variables. For example, by introducing control variables in regression models or assuring random allocation of participants in isolated experimental conditions. Whereas in ABMs, there are different approaches/preferences: KISS versus KIDS (Edmonds & Moss, 2004). KISS (Keep It Simple Stupid) advocates for keeping it simple as possible: only complexify if the simple model is not adequate. KIDS (Keep It Descriptive Stupid), on the other end of the spectrum, embraces complexity by relating to the target phenomenon as much as one can and only simplify when evidence justifies it. Either way, the idea of control in ABM is to avoid an explosion of complexity that impedes the understanding of the model, that can lead to e.g., causes misleading interpretations of emergent outcomes due to meaningless artefacts.
We summarise some core take-aways from our comparison discussions in Table 1.
Table 1. Comparing models in social psychology and agent-based social simulation
Social psychology (VBM)
Social Simulation (ABM)
Aim
Theory development and prediction (variable level)
Not predefined. Can vary widely purpose. (system level)
Model target
Replicate and test relations between variables
Reproduce and/or explain a social phenomenon – the macro level pattern
Composed of
Variables and relations between them
Agents, environment & interactions
Strive for
High control, (low number of variables and relations Replication
Purpose-dependent. Model complexity: represent what is needed, not more, not less.
Testing
Hypotheses testing using statistics, including possible measuring the effect size a relation to assess confidence in the variable’s importance’
Purpose-dependent. Can refer to verification, validation, sensitivity analysis or all of them. See text and refs under false friends.
Causality
(or correlation) between variables Linear representation
Between variables and/or model entities. Non-linear representation
Theory development
Critical reflection on theory through confirmation. Through hypothesis testing (a prediction) theory gets validated or (if not confirmed) input for reconsideration of the theory.
IFF aim of model, ways of doing is not predefined. It can be reproducing the theory prediction with or without internal validity. ABMs can further help to identify gaps in existing theory.
Dynamism
Little – often within snapshot causality
Core – within snapshot and over time causality
External validity(the ability to say something about the actual target/ empirical phenomenon)
VBM aims at generalisation and has predictive value for the phenomenon in focus. VBMs in lab experiments are often criticised for their weak external validity, considered high for field experiments.
ABMs insights are about the model, not directly about the real world. Without making predictive claims, they often do aim to say something about the real world.
Beyond blind spots, towards complementary powers
We shared the result of our discussions, the (seemingly) communalities and differences between models in social psychology and agent-based social simulation. We allowed for a peek into the content of our interdisciplinary journey as we invested time, allowed for trust to grow, and engaged in open communication. All of this was needed in the attempt to uncover conflicting ways of seeing and studying the social identity approach (SIA). This investment was crucial to be able to make progress in formalising SIA in ways that enable for deeper insights – formalisations that are in line with SIA theories, but also to push the frontiers in SIA theory. Joining forces allows for deeper insights, as VBM and ABM complement and challenge each other, thereby advancing the frontiers in ways that cannot be achieved individually (Eberlen, Scholz & Gagliolo, 2017; Wijermans et al. 2022,). SIA social psychologists bring to the table the deep understanding of the many facets of SIA theories and can engage in the negotiation dance of the formalisation process adding crucial understanding of the theories, placed in their theoretical context. Social psychology in general can point to empirically supported causal relations between variables, and thereby increase the realism of the assumptions of agents (Jager, 2017; Templeton & Neville 2020). Agent-based social simulation, on the other hand, pushes for over-time causality representation, bringing to light (logical) gaps of a theory and providing explicitness and thereby adding to the development of testable (extended) forms of (parts of) a theory, including the execution of those experiments that are hard or impossible in controlled experiments. We thus started our journey, hoping to shed some light on blind spots and releasing our complementary powers in the formalisation of SIA.
To conclude, we felt that having a conversation together led to a qualitatively different understanding than would have been the case had we all ‘just’ reading informative papers. These conversations reflect a collaborative research process (Schlüter et al. 2019). In this RofASSS paper, we strive for widening this conversation to the social simulation community, connecting with others about our thoughts as well as hearing your experiences, thoughts and learnings while being on an interdisciplinary journey with minds shaped by variable-based or agent-based models, or both.
Acknowledgements
The many conversations we had in this stimulating scientific network since 2020 were funded by the the Deutsche Forschungsgemeinschaft (DFG- 432516175)
References
Conte, R., & Paolucci, M. (2014). On agent-based modeling and computational social science. Frontiers in psychology, 5, 668. DOI:10.3389/fpsyg.2014.00668
David, N., Fachada, N., & Rosa, A. C. (2017). Verifying and validating simulations. In Simulating social complexity (pp. 173-204). Springer, Cham. DOI:10.1007/978-3-319-66948-9_9
Eberlen, J., Scholz, G., & Gagliolo, M. (2017). Simulate this! An introduction to agent-based models and their power to improve your research practice. International Review of Social Psychology, 30(1). DOI:10.5334/irsp.115/
Edmonds, B., & Moss, S. (2004). From KISS to KIDS–an ‘anti-simplistic’modelling approach. In International workshop on multi-agent systems and agent-based simulation (pp. 130-144). Springer, Berlin, Heidelberg. DOI:10.1007/978-3-540-32243-6_11
Edmonds, B., Le Page, C., Bithell, M., Chattoe-Brown, E., Grimm, V., Meyer, R., Montañola-Sales, C., Ormerod, P., Root, H. and Squazzoni, F. (2019) ‘Different Modelling Purposes’ Journal of Artificial Societies and Social Simulation 22 (3) 6 <http://jasss.soc.surrey.ac.uk/22/3/6.html>. doi: 10.18564/jasss.3993
Gilbert, N., & Troitzsch, K. (2005). Simulation for the social scientist. McGraw-Hill Education (UK).
Jager, W. (2017). Enhancing the realism of simulation (EROS): On implementing and developing psychological theory in social simulation. Journal of Artificial Societies and Social Simulation, 20(3). https://jasss.soc.surrey.ac.uk/20/3/14.html
Lorenz, J., Neumann, M., & Schröder, T. (2021). Individual attitude change and societal dynamics: Computational experiments with psychological theories. Psychological Review, 128(4), 623-642. https://doi.org/10.1037/rev0000291
Schlüter, M., Orach, K., Lindkvist, E., Martin, R., Wijermans, N., Bodin, Ö., & Boonstra, W. J. (2019). Toward a methodology for explaining and theorizing about social-ecological phenomena. Current Opinion in Environmental Sustainability, 39, 44-53. DOI:10.1016/j.cosust.2019.06.011
Smith, E.R. & Conrey, F.R. (2007): Agent-based modeling: a new approach for theory building in social psychology. Pers Soc Psychol Rev, 11:87-104. DOI:10.1177/1088868306294789
Templeton, A., & Neville, F. (2020). Modeling collective behaviour: insights and applications from crowd psychology. In Crowd Dynamics, Volume 2 (pp. 55-81). Birkhäuser, Cham. DOI:10.1007/978-3-030-50450-2_4
Wijermans, N., Schill, C., Lindahl, T., & Schlüter, M. (2022). Combining approaches: Looking behind the scenes of integrating multiple types of evidence from controlled behavioural experiments through agent-based modelling. International Journal of Social Research Methodology, 1-13. DOI:10.1080/13645579.2022.2050120
Notes
[1] Most VBMs are linear (or multilevel linear models), but not all. In the case of non-normally distributed data changes the tests that are used.
[2] We are researchers keen to use, extend, and test the social identity approach (SIA) using agent-based modelling. We started from interdisciplinary DFG network project (SIAM: Social Identity in Agent-based Models, https://www.siam-network.online/) and now form a continuous special-interest group at the European Social Simulation Association (ESSA) http://www.essa.eu.org/.
[3] ABMs can cater to diverse purposes, e.g., description, explanation, prediction, theoretical exploration, illustration, etc. (Edmonds et al., 2019).
Wijermans, N., Scholz, G., Paolillo, R., Schröder, T., Chappin, E., Craig, T. and Templeton, A. (2022) Models in Social Psychology and Agent-Based Social simulation - an interdisciplinary conversation on similarities and differences. Review of Artificial Societies and Social Simulation, 4 Oct 2022. https://rofasss.org/2022/10/04/models-in-spabss/
The Journal of Artificial Societies and Social Simulation (hereafter JASSS) retains a distinctive position amongst journals publishing articles on social simulation and Agent-Based Modelling. Many journals have published a few Agent-Based Models, some have published quite a few but it is hard to name any other journal that predominantly does this and has consistently done so over two decades. Using Web of Science on 25.07.22, there are 5540 hits including the search term <“agent-based model”> anywhere in their text. JASSS does indeed have the most of any single journal with 268 hits (5% of the total to the nearest integer). The basic search returns about 200 distinct journals and about half of these have 10 hits or less. Since this search is arranged by hit count, this means that the unlisted journals have even fewer hits than those listed i. e. less than 7 per journal. This supports the claim that the great majority of journals have very limited engagement with Agent-Based Modelling. Note that the point here is to evidence tendencies effectively and not to claim that this specific search term tells us the precise relative frequency of articles on the subject of Agent-Based Modelling in different journals.
This being so, it seems reasonable – and desirable for other practical reasons like being entirely open access, online and readily searchable – to use JASSS as a sample – though clearly not necessarily a representative sample – of what may be happening in Agent-Based Modelling more generally. This is the case study approach (Yin 2009) where smaller samples may be practically unavoidable to discuss richer or more complex phenomena like the actual structures of arguments rather than something quantitative like, say, the number of sources cited by each article.
This piece is motivated by the scepticism that some reviewers have displayed about such a case study approach focused on JASSS and conclusions drawn from it. It is actually quite strange to have the editors and reviewers of a journal argue against its ability to tell us anything useful about wider Agent-Based Modelling research even as a starting point (particularly since this approach has been used in articles previously published in the journal, see for example, Meyer et al. 2009 and Hauke et al. 2017). Of course, it is a given that different journals have unique editorial policies, distinct reviewer pools and so on. Though this may mean, for example, that journals only irregularly publishing Agent-Based Models are actually less typical because it is more arbitrary who reviews for them and there may therefore be less reviewing skill and consensus about the value of articles involved. Anecdotally, I have found this to be true in medical journals where excellent articles rub shoulders with much more problematic ones in a small overall pool. The point of my argument is not to claim that JASSS can really stand in for ABM research as a whole – which it plainly cannot – but that, if the case study approach is to be accepted at all, JASSS is one of the few journals that successfully qualifies for it on empirically justifiable grounds. Conversely, given the potentially distinctive character of journals and the wide spread of Agent-Based Modelling, attempts at representative sampling may be very challenging in resource terms.
Method and Results
Again, using Web of Science on 04.07.22, I searched for the most highly cited articles containing the string “opinion dynamics”. I am well aware that this will not capture all articles that actually have opinion dynamics as their subject matter but this is not the intention. The intention is to describe a reproducible and measurable procedure correlated with the importance of articles so my results can be checked, criticised and extended. Comparing results based on other search terms would be part of that process. Then I took the first ten distinct journals that could be identified from this set of articles in order of citation count. The idea here was to see what journals had published the most important articles in the field overall – at least as identified by this particular search term – and then follow up their coverage of opinion dynamics generally. In addition, for each journal, I accessed the top 50 most cited articles and then checked how many articles containing the string “opinion dynamics” featured in that top 50. The idea here was to assess the extent to which opinion dynamics articles were important to the impact of a particular journal. Table 1 shows the results of this analysis.
Journal Title
“opinion dynamics” Articles in the Top 50 Most Cited
Most Highly Cited “opinion dynamics” Article Citations
Number of Articles Containing the String “opinion dynamics”
Reviews of Modern Physics
0
2380
1
JASSS
6
1616
64
International Journal of Modern Physics C
4
376
72
Dynamic Games and Applications
1
338
5
Physical Review Letters
0
325
5
Global Challenges
1
272
1
IEEE Transactions on Automatic Control
0
269
38
SIAM Review
0
258
2
Central European Journal of Operations Research
1
241
1
Physica A: Statistical Mechanics and Its Applications
0
231
143
Table 1. The Coverage, Commitment and Importance of Different Journals in Regard to “opinion dynamics”: Top Ten by Citation Count of Most Influential Article.
This list attempts to provide two somewhat separate assessments of a journal with regard to “opinion dynamics”. The first is whether it has a substantial body of articles on the topic: Coverage. The second is whether, by the citation levels of the journal generally, “opinion dynamics” models are important to it: Commitment. These journals have been selected on a third dimension, their ability to contribute at least one very influential article to the literature as a whole: Importance.
The resulting patterns are interesting in several ways. Firstly, JASSS appears unique in this sample in being a clearly social science journal rather than a physical science journal or one dealing with instrumental problems like operations research or automatic control. It is an interesting corollary how many “opinion dynamics” models in a physics journal will have been reviewed by social scientists or modellers with a social science orientation at least. This is part of a wider question about whether, for example, physics journals are mainly interested in these models as formal systems rather than as having likely application to real societies. Secondly, 3 journals out of 10 have only a single “opinion dynamics” article – and a further journal has only 2 – which are nonetheless, extremely highly cited relative to such articles as a whole. It is unclear whether this “only one but what a one” pattern has any wider significance. It should also be noted that the most highly cited article in JASSS is four times more highly cited than the next most cited. Only 4 of these journals out of 10 could really be said to have a usable sample of such articles for case study analysis. Thirdly, only 2 journals out of 10 have a significant number of articles sufficiently important that they appear in the top 50 most cited and 5 journals have no “opinion dynamics” articles in their top 50 most cited at all. This makes the point that a journal can have good coverage of the topic and contain at least one highly cited article without “opinion dynamics” necessarily being a commitment of the journal.
Thus it seems that to be a journal contributing at least one influential article to the field as a whole, to have several articles that are amongst the most cited by that journal and to have a non-trivial number of articles overall is unusual. Only one other journal in the top 10 meets all three criteria (International Journal of Physics C). This result is corroborated in Table 2 which carries out the same analysis for all additional journals containing at least one highly cited “opinion dynamics” article (with an arbitrary cut off of at least 100 citations for that article). There prove to be fourteen such journals in addition to the ten above.
Journal Title
“opinion dynamics” Articles in the Top 50 Most Cited
Most Highly Cited “opinion dynamics” Article Citations
Number of Articles Containing the String “opinion dynamics”
Mathematics of Operations Research
1
215
2
Information Sciences
0
186
14
Physica D: Nonlinear Phenomena
0
182
4
Journal of Complex Networks
1
177
5
Annual Reviews in Control
2
165
4
Information Fusion
0
154
11
IEEE Transactions on Control of Network Systems
3
151
12
Automatica
0
141
32
Public Opinion Quarterly
0
132
5
Physical Review E
0
129
74
SIAM Journal on Control and Optimization
0
127
13
Europhysics Letters
0
116
3
Knowledge-Based Systems
0
112
5
Scientific Reports
0
111
26
Table 2. The Coverage, Commitment and Importance of Different Journals in Regard to “opinion dynamics”: All Remaining Distinct Journals whose most important “opinion dynamics” article receives at least 100 citations.
Table 2 confirms the dominance of physical science journals and those solving instrumental problems as opposed to those evidently dealing with the social sciences: A few terms like complex networks are ambivalent in this regard however. Further it confirms the scarcity of journals that simultaneously contribute at least one influential article to the wider field, have a sensibly sized sample of articles on this topic – so that provisional but nonetheless empirical hypotheses might be derived from a case study – and have “opinion dynamics” articles in their top 50 most cited articles as a sign of the importance of the topic to the journal and its readers. To some extent, however, the latter confirmation is an unavoidable artefact of the sampling strategy. As the most cited article becomes less highly cited, the chance it will appear in the top 50 most cited for a particular journal will almost certainly fall unless the journal is very new or generally not highly cited.
As a third independent check, I again used Web of Science to identify all journals which had – somewhat arbitrarily – at least 30 articles on “opinion dynamics”, giving some sense of their contribution. Only two more journals (see Table 3) not already occurring in the two tables above were identified. Generally, this analysis considers only journal articles and not conference proceedings and book chapter serials whose peer review status is less clear/comparable.
Journal Title
“opinion dynamics” Articles in the Top 50 Most Cited
Most Highly Cited “opinion dynamics” Article Citations
Number of Articles Containing the String “opinion dynamics”
Advances in Complex Systems
5
54
42
Plos One
0
53
32
Table 3. The Coverage, Commitment and Importance of Different Journals: All Journals with at Least 30 “opinion dynamics” hits not already listed in Tables 1 and 2.
This cross check shows that while the additional journals do have sample of articles large enough to form the basis for a case study, they either have not yet contributed a really influential article to the wider field – less than half the number of citations of the journals which qualify for Tables 1 and 2, do not have a high commitment to opinion dynamics – in terms of impact within the journal and among its readers – or both.
Before concluding this analysis, it is worth briefly reflecting on what these three criteria jointly tell us – though other criteria could also be used in further research. By sampling on highly cited articles we focus on journals that have managed to go beyond their core readership and influence the field as a whole. There is a danger that journals that have never done this are merely “talking to themselves” and may therefore form a less effective basis for a case study speaking to the field as a whole. By attending to the number of articles in the top 50 for the journal, we get a sense of whether the topic is central (or only peripheral) to that journal/its readership and, again, journals where the topic is central stand a chance of being better case studies than those where it is peripheral. The criteria for having enough articles is simply a practical one for conducting a meaningful case study. Researchers using different methods may disagree about how many instances you need to draw useful conclusions but there is general agreement that it is more than one!
Analysis and Conclusions
The present article was motivated by an attempt to evaluate the claim that JASSS may be parochial and therefore not constitute a suitable basis for provisional hypotheses generated by case study analysis of its articles. Although the argument presented here is clearly rough and ready – and could be improved on by subsequent researchers – it does not appear to support this claim. JASSS actually seems to be one of very few journals – arguably the only social science one – that simultaneously has made at least one really influential contribution to the wider field of opinion dynamics, has a large enough number of articles on the topic for plausible generalisation and has quite a few such articles in its top 50, which shows the importance of the topic to the journal and its wider readership. Unless one wishes to reject case study analysis altogether, there are – in fact – very few other journals on which it can effectively be done for this topic.
But actually, my main conclusion is a wider reflection on peer reviewing, sampling and scientific progress based on reviewer resistance to the case study approach. There are 1386 articles with the search term “opinion dynamics” in Web of Science as of 25.07.22. It is clearly not realistic for one article – or even one book – to analyse all that content, particularly qualitatively. This being so we have to consider what is practical and adequate to generate hypotheses suitable for publication and further development of research along these lines. Case studies of single journals are not the only strategy but do have a recognised academic tradition in methodology (Brown 2008). We could sample randomly from the population of articles but I have never yet seen such a qualitative analysis based on sampling and it is not clear whether it would be any better received by potential reviewers. (In particular, with many journals each having only a few examples of Agent-Based Models, realistically low sampling rates would leave many journals unrepresented altogether which would be a problem if they had distinctive approaches.) Most journals – including JASSS – have word limits and this restricts how much you can report. Qualitative analysis is more drawn-out than quantitative analysis which limits this research style further in terms of practical sample sizes. Both reading whole articles for analysis and writing up the resulting conclusions takes more resources of time and word count. As long as one does not claim that a qualitative analysis from JASSS can stand for all Agent-Based Modelling – but is merely a properly grounded hypothesis for further investigation – and shows ones working properly to support that further investigation, it isn’t really clear why that shouldn’t be sufficient for publication. Particularly as I have now shown that JASSS isn’t notably parochial along several potentially relevant dimensions. If a reviewer merely conjectures that your results won’t generalise, isn’t the burden of proof then on them to do the corresponding analysis and publish it? Otherwise the danger is that we are setting conjecture against actual evidence – however imperfect – and this runs the risk of slowing scientific progress by favouring research compatible with traditionally approved perspectives in publication. It might be useful to revisit the everyday idea of burden of proof in assessing the arguments of reviewers. What does it take in terms of evidence and argument (rather than simply power) for a comment by a reviewer to scientifically require an answer? It is a commonplace that a disproved hypothesis is more valuable to science than a mere conjecture or something that cannot be proven one way or another. One reason for this is that scientific procedure illustrates methodological possibility as well as generating actual results. A sample from JASSS may not stand for all research but it shows how a conclusion might ultimately be reached for all research if the resources were available and the administrative constraints of academic publishing could be overcome.
As I have argued previously (Chattoe-Brown 2022), and has now been pleasingly illustrated (Keijzer 2022), this situation may create an important and distinctive role for RofASSS. It may be valuable to get hypotheses, particularly ones that potentially go against the prevailing wisdom, “out there” so they can subsequently be tested more rigorously rather than having to wait until the framer of the hypothesis can meet what may be a counsel of perfection from peer reviewers. Another issue with reviewing is a tendency to say what will not do rather than what will do. This rather the puts the author at the mercy of reviewers during the revision process. RofASSS can also be used to hive off “contextual” analyses – like this one regarding what it might mean for a journal to be parochial – so that they can be developed in outline for the general benefit of the Agent-Based Modelling community – rather than having to add length to specific articles depending on the tastes of particular reviewers.
Finally, as should be obvious, I have only suggested that JASSS is not parochial in regard to articles involving the string “opinion dynamics”. However, I have also illustrated how this kind of analysis could be done systematically for different topics to justify the claim that a particular journal can serve as a reasonable basis for a case study.
Acknowledgements
This analysis was funded by the project “Towards Realistic Computational Models Of Social Influence Dynamics” (ES/S015159/1) funded by ESRC via ORA Round 5.
References
Brown, Patricia Anne (2008) ‘A Review of the Literature on Case Study Research’, Canadian Journal for New Scholars in Education/Revue Canadienne des Jeunes Chercheures et Chercheurs en Éducation, 1(1), July, pp. 1-13, https://journalhosting.ucalgary.ca/index.php/cjnse/article/view/30395.
Chattoe-Brown, E. (2022) ‘If You Want to Be Cited, Don’t Validate Your Agent-Based Model: A Tentative Hypothesis Badly in Need of Refutation’, Review of Artificial Societies and Social Simulation, 1st Feb 2022. https://rofasss.org/2022/02/01/citing-od-models
Hauke, Jonas, Lorscheid, Iris and Meyer, Matthias (2017) ‘Recent Development of Social Simulation as Reflected in JASSS Between 2008 and 2014: A Citation and Co-Citation Analysis’, Journal of Artificial Societies and Social Simulation, 20(1), 5. https://www.jasss.org/20/1/5.html. doi:10.18564/jasss.3238
Meyer, Matthias, Lorscheid, Iris and Troitzsch, Klaus G. (2009) ‘The Development of Social Simulation as Reflected in the First Ten Years of JASSS: A Citation and Co-Citation Analysis’, Journal of Artificial Societies and Social Simulation, 12(4), 12,. https://www.jasss.org/12/4/12.html.
Yin, R. K. (2009) Case Study Research: Design and Methods, fourth edition (Thousand Oaks, CA: Sage).
Chattoe-Brown, E. (2022) Is The Journal of Artificial Societies and Social Simulation Parochial? What Might That Mean? Why Might It Matter? Review of Artificial Societies and Social Simulation, 10th Sept 2022. https://rofasss.org/2022/09/10/is-the-journal-of-artificial-societies-and-social-simulation-parochial-what-might-that-mean-why-might-it-matter/
1Escuela de Ciencias Empresariales, Universidad Católica del Norte, Coquimbo, Chile, and CESIMO, Universidad de Los Andes, Mérid.
2CEMISID, Universidad de Los Andes, Merida, Venezuela; GIDITIC, Universidad EAFIT, Medellin, Colombia; and Universidad de Alcala, Dpto. Automatica, Alcala de Henares, Spain.
Abstract.
This work suggests to complementarily use Multi-Fuzzy Cognitive Maps (MFCM) and Multi-agent Based Simulation (MABS) for social simulation studies, to overcome deficiencies of MABS for contextually understanding social systems, including difficulties for considering the historical and political domains of the systems, variation of social constructs such as goals and interest, as well as modeler’s perspective and assumptions. MFCM are a construction much closer than MABS to natural language and narratives, used to model systems appropriately conceptualized, with support of data and/or experts in the modeled domains. Diverse domains of interest can be included in a MFCM, permitting to incorporate the history and context of the system, explicitly represent and vary agents’ social constructs, as well as take into account modeling assumptions and perspectives. We briefly describe possible forms of complementarily use these modeling paradigms, and exemplifies the importance of the approach by considering its relevance to investigate othering and polarization.
1. Introduction
In order to understand better issues such as othering and polarization, there is a claim in social simulation for research that includes the important domains of history, politics and game of power, as well as for greater use of social science data, make more explicit and conscious about the models’ assumptions, and be more cautious in relation to the interpretation of the simulations’ results (Edmonds et al., 2020). We describe a possible form of dealing with these difficulties: combining Multi-Agent based Simulation (MABS) and Multi Fuzzy Cognitive Maps (MFCM) (or other forms of cognitive maps), suggesting new forms of dealing with complexity of social behavior. By using MFCM an alternative modeling perspective to MABS is introduced, which facilitates expressing the context of the model, and the modelers’ assumptions, as suggested in Terán (2004). We will consider as a case studying othering and polarization, given the difficulties for modeling it via MABS (Edmonds et al., 2020). Our proposal permits to explicitly represent social constructs such as goals, interest and influence of powerful actors on, e.g., people’s othering and polarization, and so in better contextualizing the simulated model. Variations of social constructs (e.g., goals, othering, polarization, interests) can be characterized and modeled by using MFCM.
Combined use of MABS and Fuzzy Cognitive Maps (FCM) (MFCM, multi FCM, are an extension of FCM, see the Annex) has already been suggested, see for example Giabbanelli (2017). MABS develop models at the micro level, while FCM and MFCM permits us to create models at the macro or contextual level; the idea is to use one to complement the other, i.e., to generate rich feedback between them and enhance the modeling process. Additionally, Giabbanelli propose FCM as a representation closer than MABS to natural language, allowing more participatory models, and better representation of the decision making process. Giabbanelli recommend forms of combining these two modeling approaches, highlighting key questions modelers must be careful about. In this line, we also propose a combined usage of a MFCM and MABS to overcome deficiencies of MABS modelling in Social Simulation.
Initially (in section 2) we offer a description of human societies from a broad view point, which recognizes their deep complexities and clarifies the need for better contextualizing simulation models, allowing modeling of diverse agents’ constructs, and making explicit modelers’ assumptions and perspectives. Afterwards (in section 3), we briefly review the drawbacks of MABS for modeling some of these deep complexities. Then (in section 4), MFCM are briefly described, supported on a brief technical account in the Annex. Following (in section 5), we suggest to complementarily use MABS and MFCM for having a more comprehensive representation of human societies and their context, e.g., to better model problems such as othering and polarization. MFCM will model context and give a conceptual mark for MABS (allowing to model variation of context, e.g., changes of agents’ interests or goals, making explicit modelers’ perspective and assumptions, among other advantages), which, in turn, can be used to explore in detail specific configurations or scenarios of interest suggested by the MFCM. Finally (in section 6), some conclusions are given.
2. (A wide view of) Human societies and influence of communication media on actual culture
As humans and primates, we recognise the social groups within which we develop as people (e.g., family, the community where we grow up, partners at the school or at work) as part of our “large home”, in which its members develop a common identity, with strong rational and emotional links. Other groups beyond these close ones are “naturally” estrangers for us and its members “instinctively” seen as others. In large civilizations such as western society, we extend somewhat these limits to include nations, in certain respects. In groups we develop perspectives, follow certain myths and rites, and have common interests, viewpoints about problems, solutions for these, and give meaning to our life. Traditionally, human societies evolve from within groups by direct face to face interaction of its members, with diverse perspectives, goals, interest, and any other social construct with respect to other groups. Nowadays this evolution mainly from natural interaction has been importantly altered in some societies, especially western and western influenced societies, where social media has introduced a new form of communication and grouping: virtual grouping. Virtual grouping consists in the creation of groups, either formally or informally, by using the internet, and social networks such as Facebook, Instagram, etc. In this process, we access certain media sites, while discarding others, in accordance with our preferences, which in turn depends on our way of thinking and preferences created in social, both virtual and direct (face to face), interaction. Currently, social media, and traditional media (TV, newspapers, etc.) have a strong influence on our culture, impacting on ours myths, rites, perspectives, forms of life, goals, interests, opinion, reasoning, emotions, and othering.
Characteristics of virtual communication, e.g., anonymity, significantly impacts on all these constructs, which, differently from natural interaction, have a strong potential to promote polarization, because of several reasons, e.g., given that virtual environments usually create less reflexive groups, and emotional communication is poorer or lack deepness. Virtual interaction is poorer than direct social interaction: the lack of physical contact strongly reduces our emotional and reflexive connection. Virtual social interaction is “colder” than direct social interaction; e.g., lack of visual contact stops communication of many emotions that are transmitted via gestures, and prevents the call for attention from the other that visual contact and gestures demands.
Even more, many times sources and veracity of information, comments, ideas, and whatever is in social media, are not clear. Even more, fake news are common in social media, what generate false beliefs, and behavior of people influenced and somewhat controlled by those who promote fake news. Fake news can in this sense generate polarisation, as some groups in the society prefer certain media, and other groups choose a different one. As these media may promote different perspectives following interest of powerful actors (e.g., political parties), conflicting perspectives are induced in the different groups, what in turn generates polarization. Social media are highly sensitive to manipulation by powerful actors worldwide, including governments (because of, e.g., their geopolitical interests and strategies), corporations (in accordance with their economic goals), religious groups, political parties, among many others. Different groups of interests influence in direct and indirect, visible and hidden, forms the media, following a wide diversity of strategies, e.g., those of business marketing, which are supported by knowledge of people (e.g., psychology, sociology, games theory, etc.). Thus, the media can create and contribute to create visions of the word, or perspectives, in accordance with the interest of powerful international or national actors. For more about all this, see, e.g, Terán and Aguilar (2018).
As a consequence, people following media that promotes a world view, related with some powerful actor(s) (e.g., a political party or a group of governments) virtually group around media that support this world view, while other people do the same in relation to other media and powerful actor(s), who promote(s) a different perspective, which many times is in conflict with the first one. Thus, grouping following the media sometimes promotes groups with conflicting perspectives, goals, interests, etc., which generates polarization. We can find examples of this in diverse regions and countries of the world. The media has important responsibility for polarization in a diversity of issues such as regional integration in Europe, war in Ukraine, migrations from Middle East or Africa to Europe, etc. Consequently, media manipulation sometimes allow powerful actors to influence and somewhat control perspectives and social behavior. Even more, the influence of social media on people is sometimes stronger than the influence of direct social interaction. All these introduce deep complex issues in social human interaction and behavior. This is why we have chosen polarization as the case study for his essay.
Consequently, to comprehend actual human behavior, and in particular polarization, it is necessary to appropriately take into account the social context, what permits to understand better the actual complexity of social interaction, e.g., how powerful international, national, and local actors’ influence on media affects people perspectives, goals, interest, and polarization, as well as their strategies and actions in doing so. Contextualized modeling will help in determining social constructs (goals, interests, etc.) in certain situations, and their variation from situation to situation. For this, we suggest complementing MABS with MFCM. For more about the consequences of virtual interaction, see for example Prensky (2001a, 2001b). Prensky (2009) has also suggested forms to overcome such consequences: to promote digital wisdom. MABS and MFCM models will help in defining forms of dealing with the problems of high exposure to social networks, in line with Prensky’s concerns.
3. Weakness of the MABS approach for modeling context
Edmonds et al. (2020) recognize that MABS models assume a “state of the world” or “state of nature” that does not include the historical context of the agent, e.g., in such a way that they explicitly present goals, interests, etc., and pursue them via political actions, sometimes exerting power over others. For instance, the agents can not change their goals, interests or desires during the simulation, to show certain evolution, as a consequence of reflection and experience at the level of desires, allowing cognitive variations. The models are strongly limited in relation to representing the context of the social interaction, which in part determines variation of important factors of agents’ behavior, e.g., goals. This, to a good extent, is due to lack of representation of the agents’ context. For the same reason, it is difficult to represent modelers assumptions and perspectives, which might also be influenced by social media and powerful actors, as explained above.
The Special Issue of the Social Science Computer Review. (Volume 38, Issue 4, August 2020, see for instance Edmonds et al. (2020) and Rocco and Wander (2020)), presents several models aiming at dealing with some of these drawbacks of MABS, specifically, to relate models to social science data, be more aware about the models’ assumptions, and be more cautious in relation to the interpretation of the simulations’ results. However, in these works diverse difficulties are not addressed, e.g., having appropriate representation of the context in order to explicitly consider diverse constructs, e.g., goals and interests, as well as having a wide representation of modelers perspectives and assumptions so that diverse perspectives can be addressed and compared, among other important matters.
MABS represent social interaction, i.e., the interaction in a group, where the agent’s goal, and other social constructs are assumed given, not variable, and to understand the context where they appear is not of interest or is out of reach (too difficult). However, as explained above, agents are in diverse social groups, not only in the simulated one, and so goals, interests, and beliefs in the modeled group are shaped in accordance to their interactions in diverse groups, and the influence of multiple, virtual and natural groups in which they participate. In order to represent variations of such elements, the context must be taken into account, as well as to elaborate models from narratives. MFCM is naturally close to narratives, as it is elaborated from conceptual frameworks. In this sense, MFCM might represent an intermediate step towards MABS models. In a MFCM and in the steps towards elaborating the MABS, modelers’ perspectives and assumptions can be made explicit. In addition, MABS presents limitations to determine the conditions for which a certain behavior or tendency occurs (Terán, 2001; Terán et al. 2001), i.e., for making strong inferences and theorem proving of tendencies for subsets of the theory of the simulation, which could more easily be performed in the MFCM. Hopefully, exploring configurations of the MFCM the proof could be carried out indirectly, in a higher level than in MABS, as has already been suggested in previous papers (Aguilar et al., 2020; Perozo et al., 2013).
4. Multi-Fuzzy Cognitive Maps (MFCM)
We suggest conceptual or cognitive maps as a more flexible form than MABS to represent context of a social situation, and in particular MFCM, as implemented by Aguilar and others (see e.g., Kosko, 1986; Aguilar 2005, 2013, 2016; Aguilar et al., 2016, 2020; Contreras and Aguilar, 2010; and Sánchez et al., 2019; Puerto et al., 2019). A brief description of Fuzzy and Multi-fuzzy cognitive maps, following Sánchez et al. (2019), is given in the Annex.
Fuzzy cognitive maps help us in describing the context via qualitative (e.g., very low, low, medium, high, too high) and quantitative variables, as indicated in the annex. The system is represented by the network of concepts (variables) interrelated via weights (also given by variables). The high level of the MFCM paradigm, differently from a MABS, permits us to explicit different elements of the models such as the agents constructs (goals, interests, etc.), as well as the modelers assumptions and perspectives, as suggested in Terán (2004). MFCM will facilitate to explicit the accumulated set of assumptions (“abstraction-assumptions, design-assumptions, inference-assumptions, analysis-assumptions, interpretation-assumptions and application-assumptions”, as these are summarized in Terán, 2004).
In a MFCM, a particular situation of the system is given by a specific configuration of the weights (see, e.g., Sánchez et al., 2019). Suppose we are dealing with a model similar to that elaborated in Sánchez et al. (2019) to study the quality of opinion in a community. Sánchez et al. examine the capabilities of the MFCM for knowledge description and extraction about opinions presented in a certain topic, allowing the assessment of the quality of public opinion. Special attention is offered to the influence of the media on public opinion. The evolution of the concepts and relationships is presented. Concepts define the relevant aspects from which public opinion emerges, covering diverse domains, for instance, the social, technological and psycho-biological ones. The MFCM permits to identify the media preferred by the public in order to better understand several issues, including the high esteem that the new communication media hold.
In line with this, let us assume that we want to understand the quality of public opinion in a community of Europe about diverse issues during 2022. This network, with a certain configuration of the weights, but unspecified concepts, represents a social system with a certain structure (as the weights are given) that is in some sense general, as the values of the concepts can still vary. Variation of the concepts represents different scenarios of the social system (with a given structure, defined by the weights); e.g., the model of a European community considered in relation to three scenarios regarding the state of public opinion in relation to specific issues: 1: climate change, 2: situation of tourism in the community, 3: secondary effects of the COVID-19 vaccines. The weights of the network are determined by using a variety of scenarios; i.e., the network is trained with several scenarios, for which all possible values of the concepts are known. Once the network is trained, it can be used to infer unknown specific values of the concepts for other scenarios (following Aguilar et al. 2020; Sánchez et al. 2019; Terán y Aguilar, 2018); e.g., the state of public opinion in relation to the involvement of EU in the war in Ukraine. Even more, by exploring an appropriate set of scenarios, proofs about the state of certain concepts can be developed; e.g., that a majority of people in the community is against direct EU involvement in the war in Ukraine. The proof could be carried out for a subset of the possible configurations of a domain, several domains, or part of a domain, e.g., for the psycho-biological domain. Additionally, having an appropriate elaboration of the model would allow evaluating how polarized is the opinion of the community in relation to the involvement of EU in that war.
Diverse configurations of the MFCM can represent different modelers’ perspectives and assumptions, as well as various agents’ constructs, such as goals, interests, etc., allowing to deal with the above described drawbacks of MABS to cope with complexity of social systems.
5. Combined use of MABS and cognitive maps
The combined usage will give at least two levels of modeling: the inner, defined by the agents’ interaction concreted in a MABS, and the outer or contextual one, given by the MFCM. These will be the two last levels in the description given in 5.1. Interaction between these models occurs as the modeler interprets each model outputs and feedbacks the other. Ideally, we would have direct automatic feedback between these models.
5.1 Levels of description of the System
In order to contextually model a social system and investigate problems such as polarization, we suggest below five levels of description of the system. The first three levels are not directly associated to computational models, while levels four and five are descriptions that assist development of the computational models: MFCM and MABS, respectively. Each level gives context to the following one (the first gives context to the second, etc.). A lower level (e.g., 1. in relation to 2.) of description corresponds to a more general language, as suggested in Terán (2004). Each level must take into account the previous levels, especially the immediately superior level, which gives the most immediate context to it. This description is in line with the suggestions given in Terán (Idem). Each description makes certain assumptions and is shaped by the modeler’s perspective, which in part is coming from those actors given information to build the model. Assumptions and perspectives introduced in level of modeling i, i = 1, …, 6, can be called Assumptions-given in (i) and Perspectives-given in (i). At levels of description j, Assumption i = 1, 2, …, i are accumulated, and can be called Assumptions(j), as well as holistic Perspective(j) based on Perspectives-given in (i), i = 1, 2, .., i. These assumptions and perspectives correspond to those defined in Terán (2004) as “abstraction-assumptions, design-assumptions, inference-assumptions, analysis-assumptions, interpretation-assumptions and application-assumptions”.
Describe in natural language the system, including its relevant history, with emphasis in culture (practices, costumes, etc.) and behavior of individuals and groups relevant to the object of the study, e.g., from a historical-ontological perspective. Here, how the system has reached its actual situation is explained. This will give a global view of the society and the general form of behavior, problematics, conflicts, etc.
Describe the diverse relevant domains given context to the system of interest in accordance with the study, e.g., political, economical, dominant actors, etc., and the relationships among them. Concrete specifications of these domains sets scenarios for the real system, i.e., possible configurations of it.
Describe the particular social group of interest as part of the society explained above, in 1., and the domains given in 2., showing its particularities, e.g., culturally, in terms of interests, situation and social interaction of this group in relation with other groups in the whole society, in accordance to the problematic addressed in the study.
Elaborate a cognitive map of the situation of the social group of interest, following the description given in 2 and 3. This is a description to be represented in a computational language, such as the MFCM tool developed by Contreras and Aguilar (2010).
Describe the MABS model. The MABS model is then represented in a simulation language.
The computational MFCM (or other cognitive map) and the MABS developed following 4. and 5. are then used to generate the virtual outputs and simulation study.
5.2 Possible combined uses of MFCM and MABS.
The MFCM (in general a cognitive or conceptual map) gives context to the MABS model (modeler’s assumptions and perspectives are added in the process, as indicated above), while the MABS model represents in detail the interaction of the agents’ considered in the MFCM for a specific scenario of this, as indicated in the levels of modeling given above. With this idea in mind, among the specific forms a combined usage of ABM and MFCM, we have:
i) Offering feedback from the MFCM to the MABS. A MABS in a certain configuration can be used to generate either directly or indirectly (e.g., with additional verification or manipulations) input for a simulation model. For example, in parallel to the model presented in Sánchez et al. (2019), where the domains social, biological-psychological, technological and state of the opinion are displayed, a MABS model can be developed to represent the interaction between social entities, such as people who receive information from the media, the media itself, and powerful actors who design the agenda setting of the media. This MABS model might use diverse methodologies, e.g., endorsements or BDI, to represent social interaction, or a higher level of interaction where actors share resources, on which they have interest, as in a System of Organized Action (see, e.g., SocLab models Terán and Sibertin-Blanc, 2020; Sibertin-Blanc et al., 2013). Constructs required as inputs for the model, e.g., goals, interests, values to define the endorsements schema, etc. could be deducted from the MFCM, as direct values of some concepts or functions (mathematical, logical, etc.) of the concepts. These operations could be defined by experts in the modeled domains (e.g., media owners, academics working in the area, etc.). Ideally, we would have an isomorphic relation between some variables of the MABS and variables of the MFCM – however, this is not the usual case –. In this process, the MABS is contextualized by the MFCM, whose modeling level also permits to identify modeler’s assumptions and perspectives. Also, in a narrative, and then in the MFCM, goal, interest, and other constructs can be explicitly represented, then varied and their consequence understood in order to feedback the MABS model.
ii) Giving feedback to the MFCM from the MABS. Inputs and outputs values of the MABS simulation can be used as an input to the MFCM, e.g., as a set of scenarios to train the network and determine a certain structure of the MFCM, or to determine a specific scenario/ configuration (where both, the weights and the concepts are known).
iii) Determining conditions of correspondence among the models. By simulating the MABS associated to certain scenarios of the MFCM, or, vice-verse, by determining the scenarios of MFCM related to certain MABS, the consistency among the two models and possible errors, omissions, etc. in one of the models can be detected, and then the corrections applied. Even more, this exercise can hopefully determine certain rules or conditions of correspondence among the MABS and the MFCM.
iv) Using a model to verify properties in the other model. Once certain correspondence among the models has been determined, we can use one of the models to help in determining properties of the other. For instance, a proof of a tendency in an MABS (this has been an important area of research, Terán, 2001; Terán et al. 2001; Edmonds et al., 2006) could be developed in a much easier form in the corresponding MFCM. For this, we need to characterize the set of configurations of the MFCM corresponding to the set of configurations of the MABS for which we want to perform the proof.
These possible combined uses of MFCM and MABS do not exhaust all potentials, and diverse other alternatives could appear in accordance with the needs in a particular study. Even more, automatic feedback between MFCM (or other cognitive or conceptual map) and MABS could be implemented in the future, to facilitate the mutual contributions between the two modeling approaches. This would cover modeling requirements the MABS in itself does not support at present.
5.3 A case: Modeling othering and polarization,the case of “children with virtually mediated culture”.
We outline a possible model that considers othering and polarization. In section 2 we described a society. In a society, as virtual groups become homogeneous in beliefs, motivations, intentions and behavior, certain sort of endogamy of ideas and opinions appear, constraining the variety and richness of perspectives from which people observe and judge others, making them generally less tolerant to others, more restrictive in accepting opinions and behavior of others, so less inclusive. This has diverse additional effects, for instance, increase of polarization between virtual groups regarding a diversity of themes. Problems such as polarization occur also in children with strong usage of virtual social networks (see, Prensky, 2001a, 2001b, 2009).
To investigate this problem and support the MABS, as a case, we suggest a MFCM with four levels (see Figure 1). The goal of the models (MFCM and MABS) would be to better understand the differences between the communities of children whose interaction is basically virtually mediated and the community of children whose interaction is face to face, or direct, people to people. In general, it is of interest to determine the state of othering and polarization for diverse configurations of the MFCM. As we explained above, there are clear differences between virtual and face to face interaction, consequently the upper layers in Figure 1 are the two possible niches of cultural acquisition (costumes, points of view, etc.), during life of people (ontogenesis), namely, the virtual mediated culture and the direct, face to face, cultural acquisition. These two layers involve interaction among diverse actors (e.g., people, media and powerful actors are present in layer 2). Layer 2 represents technological actors, while layer 1 represents social interaction, but both of them might involve other elements, if required. The third level represent those biological aspects related with behavior, which are created via culture: the psycho-biological level. Both levels, 1 and 2, affect the third layer, as emotions, reasoning, etc., are founded on people interaction and have a cultural base. Constructs of behavior such as goals, interests, desires, polarization, etc., appear and can be explicitly represented at this level. This third level, in turn, impacts on the overall state of the community, e.g., on the auto-generative capacity of the society, finally affecting global society/community’s othering and polarization, as our emotions, reasoning, etc., impact on our view point, on othering, etc. These last are variables defined in terms of the previous levels. In this model, the definition of concepts such as “othering” and “polarization” is crucial, and indicates basic modeling assumptions and perspective. Finally, the overall state of society/community impacts back on the cultural niches (layers 1 and 2).
In a specific situation, the whole interaction (1) of the society or community is divided between the two niches given by layers 1 and 2, a proportion of interaction frequency occurs as virtual communication, and the compliment (one minus the proportion of virtual interaction), occurs as direct, face to face, contact. This is represented in Figure 3 by the variable “Proportion of virtual interaction type”. Changes of this variable allows us to explore diverse configurations or scenarios of interaction, ranging from total virtual interaction (null direct contact) (the variable takes the value 1), to null virtual interaction (total direct contact) (the variable takes the value 0).
Figure 1. The four levels of the MFCM. The two alternative niches structuring the psycho-biology of people are at the top of the process. The overall state represents general measures such as the auto-generative character of a social system, and attitudes including othering and polarization.
Example of possible variables in some levels (Figure 1) are:
i) Face to face interaction, and ii) virtual interaction or technological: The next variables are candidates to be at these levels. Degree of:
Coherence of the interaction (possible state: good, etc.);
Identification of the others in the interaction (good or clear, etc.);
Richness of the interaction (high or good, etc.);
Truthfulness of the messages (fairness) (e.g., good: messages and communication are fair);
Openness of the community (e.g., high: usually people is open to interact with others);
Speed of the interaction (e.g.: low, medium, …);
Intentioned influence and control of the communication by powerful actors (e.g., high, medium, low, ..);
iii) Psycho-biological level:
Reflection (state: good means that people question their experiences, and observed phenomena);
Closeness of interpretations, attitudes, desires, intentions, and plans (a high value means that people’s interpretations, etc., are not very different);
Emotion and mood;
Empathy;
Addiction to virtual interaction;
Goal;
Interest;
Immediatism (propensity to do things quickly and constantly change focus of reasoning).
iv) Overall state of people and society:
Auto-generative capacity of the society;
Capacity of people to reflect about social situations (and autonomously look for solutions);
Othering;
Polarization;
Concepts at each layer impacts concepts at the other layers. E.g., concepts of level three have a strong impact on concepts of the fourth layer, such as “polarization”, and “auto-generative character of the society”.
As indicated above, to understand the dynamics of the MFCM we can develop a wide range of scenarios, for instance, varying the switch “Proportion of virtual interaction” in the interval [0, 1], to explore a set of scenarios for which the degree of virtual interaction increases from 1 to 0, as the proportion of direct interaction decreases from 1 to 0 (the real case corresponds to an intermediate value between 1 and 0). These experiments will help us in understanding better the consequences of virtual mediated culture. Even when the outline of the model presented here might need some adjustments and improvements, the present proposal keeps its potential to reach this goal.
The MFCM will be useful to deal with many issues and questions of interest, for instance:
How social networks affect basic social attitudes such as: i) critical rationality (people’s habit for questioning and explaining their experience (issues/phenomena in their life)), ii) tolerance, iii) compromise with public well-being, and iv) othering and polarization
How social networks affect social feelings, such as empathy.
The MABS model will be elaborated in accordance with the description of the MFCM indicated above. In particular, different values of the social constructs at levels 1 and 2 (e.g., goals and interests of the actors), and the corresponding state of layer 3 (e.g., Polarization), imply diverse MABS models.
The whole network of concepts, the particular network of concepts at each level, and the definition of each concept, offers a perspective of the modelers. Different modelers can develop these elements of the model differently. Assumptions can be identified also at each level. Both, perspectives and assumptions come from the modelers as well as from the theories, consult to experts to create the model, etc.. An specific model is not part of this essay, but rather a subject of future work.
6. Conclusion
Social simulation has been widely recognized as an alternative to study social systems, using diverse modeling tools, including MABS, which, however, present some limitations, like any other research tool. One of the deficiencies of MABS is their limitations to contextually modeling social systems; e.g., to suitably include the historical and political contexts or domains; difficulties to represent variation of agents’ constructs, e.g., goals and interest; and drawbacks to made explicit modeler’s assumptions and perspectives. In this paper, we have suggested to mutually complement MABS and MFCM, to overcome MABS drawbacks, to potentiate the usefulness of MABS to represent social systems.
We argue that the high level of the MFCM paradigm permits us to express different elements of the models such as the agents’ constructs (goals, interests, etc.), as well as the modelers assumptions and perspectives, as suggested in Terán (2004). Thus, MFCM facilitates the identification of the accumulated set of assumptions during the modeling process. Even more, diverse configurations of a MFCM can represent diverse modelers’ perspectives and assumptions, as well as diverse agents constructs, such as goals, interests, etc., allowing to deal with the above described complexity. This permits us to more realistically elaborate models of a wide diversity of social problems, e.g., polarization, and consequences of the influence of social networks in culture.
Among the forms MFCM and MABS complement each other we have identified the followings: mutual feedbacking of variables and concepts between the MFCM and the MABS, determining conditions of correspondence among the models, what facilitate other modeling needs, e.g., using a model to verify properties in the other model (e.g., proofs required in a MABS could be carried out in a corresponding MFCM).
A case study was outlined to exemplify the problematic that can be addressed and the advantages of using MFCM to complement MABS: Modeling othering and polarization, the case of children with virtually mediated culture. Combined use of MFCM and MABS in this case will contribute to understand better the problems created by the high use of digital interaction, especially social networks, as described by Prensky (2001a, 2001b, 2009), given that virtual interaction has strong influence on our culture, impacting on ours myths, rites, perspectives, goals, interests, opinion, othering and polarization, etc. Characteristics of virtual communication, e.g., anonymity, significantly impacts on all these constructs, which, differently from natural interaction, have a strong potential to promote certain tendencies of such constructs, e.g., polarization or our opinions, because of several reasons, for instance, given that virtual environments usually create less reflexive groups, while emotional communication is poorer or lack deepness. It is difficult to represent all these dynamics in a MABS, but it can be alternatively expressed in a MFCM.
The purpose of the work was to give an outline of the proposal; future work will be conducted to wholly develop concrete study cases with complementary MABS and MFCM models.
References
Aguilar, J. (2005). A Survey about Fuzzy Cognitive Maps Papers. International journal of computational cognition 3 (2), pp. 27-33.
Aguilar, J. (2013) Different Dynamic Causal Relationship Approaches for Cognitive Maps”, Applied Soft Computing, Elsevier, 13(1), pp. 271–282.
Aguilar, J. (2016) “Multilayer Cognitive Maps in the Resolution of Problems using the FCM Designer Tool”, Applied Artificial Intelligence, 30 (7), pp. 720-743.
Aguilar J., Hidalgo J., Osuna F., Perez N.(2016) Multilayer Cognitive Maps to Model Problems”, Proc. IEEE World Congress on Computational Intelligence, pp. 1547-1553, 2016.
Aguilar Jose, Yolmer Romero y OswaldoTerán (2020). “Analysis of the effect on the marketing of the sport product from the “par Conditio” principle in Latin American football and baseball competitions”. Submitted to International Journal of Knowledge-Based and Intelligent Engineering Systems.
Contreras, J. Aguilar, J. (2010). “The FCM Designer Tool”. Fuzzy Cognitive Maps: Advances in Theory, Methodologies, Tools and Application (Ed. M. Glykas), Springer, pp. 71-88, 2010.
Edmonds, B. and Hales, D. and Lessard-Phillips, L.(2020). Simulation Models of Ethnocentrism and Diversity: An Introduction to the Special Issue. Social Science Computer Review. Volume 38 Issue 4, August 2020, 359–364, https://journals.sagepub.com/toc/ssce/38/4
Edmonds Bruce, Oswaldo Terán y Grary Polhill (2006). “To the Outer Limits and Beyond –characterising the envelope of social simulation trajectories”, Proceedings of theThe First World Congress on Social Simulation WCSS”, Kyoto, 21-25 Agosto, 2006.
Giabbanelli Philippe, Steven Gray and Payam Aminpour (2017), Combining fuzzy cognitive maps with agent-based modeling: Frameworks and pitfalls of a powerful hybrid modeling approach to understand human-environment interactions, Environmental Modeling and Software, September 2017, 95:320-325 DOI:10.1016/j.envsoft.2017.06.040
Kosko, B. (1986). Fuzzy Cognitive Maps. International Journal of Man-Machine Studies 24, pp. 65-75.
Perozo Niriaska, Jose Aguilar, Oswaldo Terán y Heidi Molina (2013). A Verification Method for MASOES, IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, Vol 43, num 1, February, pp. 64-76, ISBN: 1083-4419. DOI: 10.1109/TSMCB.2012.2199106
Prensky, Marc (2001a). Digital Natives, Digital Immigrants Part 1, On the Horizon, Vol. 9, No. 5, September, pp 1-6. DOI: 10.1108/10748120110424816
Prensky, Marc (2001b). Do They Really Think Differently? Digital Natives, Digital Immigrants Part 2, On the Horizon, Vol. 9, No. 6, October 2001, pp 1-6. DOI: 10.1108/10748120110424843
Prensky, Marc (2009). “H. Sapiens Digital: From Digital Immigrants and Digital Natives to Digital Wisdom,” Innovate: Journal of Online Education: Vol. 5 : Issue 3, Article 1. Available at: https://nsuworks.nova.edu/innovate/vol5/iss3/1
Puerto E., Aguilar J., Chávez D., López C. (2019) Using Multilayer Fuzzy Cognitive Maps to Diagnose Autism Spectrum Disorder, Applied Soft Computing Journal, 75, pp. 58–71.
Rocco Paolillo, and Wander Jager (2020). Simulating Acculturation Dynamics Between Migrants and Locals in Relation to Network Formation, Social Science Computer Review. Volume 38 Issue 4, August 2020, pp. 365–386. https://journals.sagepub.com/toc/ssce/38/4
Sánchez Hebert, Jose Aguilar, Oswaldo Terán, José Gutiérrez de Mesa (2019). “Modeling the process of shaping the public opinion through Multilevel Fuzzy Cognitive Maps”, Applied Soft Computing, Volume 85. https://doi.org/10.1016/j.asoc.2019.105756.
Sibertin-Blanc, C., Roggero, P., Adreit, F., Baldet, B., Chapron, P., El-Gemayel, J., Mailliard, M., and Sandri, S. (2013). “SocLab: A Framework for the Modeling, Simulation and Analysis of Power in Social Organizations”, Journal of Artificial Societies and Social Simulation (JASSS), 16(4). http://jasss.soc.surrey.ac.uk/
Terán Oswaldo (2001). Emergent Tendencies in Multi-Agent Based Simulations Using Constraint-Based Methods to Effect Practical Proofs Over Finite Subsets of Simulation Outcomes, Doctoral Thesis, Centre for Policy Modelling, Manchester Metropolitan University, 2001.
Terán Oswaldo (2004). Understanding MABS and Social Simulation: Switching Between Languages in a Hierarchy of Levels, Journal of Artificial Societies and Social Simulation vol. 7, no. 4. http://jasss.soc.surrey.ac.uk/7/4/5.html
Terán Oswaldo, Edmonds Bruce and Steve Wallis (2001) “Mapping the Envelope of Social Simulation Trajectories”, Lecture Notes in Artificial Intelligence (Subserie de Lecture Notes in Computer Science): MABS, Volume 1979, pp. 229-243, Springer, Alemania, 2001
Terán Oswaldo y Jose Aguilar (2018). “Modelo del proceso de influencia de los medios de comunicación social en la opinión pública”, EDUCERE, 21 (71), Universidad de Los Andes, Mérida, Venezuela. https://www.redalyc.org/toc.oa?id=356&numero=56002
Terán Oswaldo and Christophe Sibertin-Blanc (2020). Impact on Cooperation of altruism, tenacity, and the need of a resource, accepted in IEEE Transactions on Computational Social Systems. DOI: 10.1109/TCSS.2021.3136821.
Annex. Fuzzy Cognitive Maps (FCM) and Muti-Fuzzy Cognitive Maps (MFCM).
Cognitive map theory is based on symbolic representation for the description of a system. It uses information, knowledge and experience, to describe particular domains using concepts (variables, states, inputs, outputs), and the relationships between them (Aguilar 2005, 2013, 2016). Cognitive maps can be understood as directed graphs, whose arcs represent causal connections between the nodes (concepts), used to denote knowledge. An arc with a positive sign (alternatively, negative sign), going from node X to node Y means that X (causally) increases (alternatively, decreases) Y. Cognitive maps are graphically represented: concepts are connected by arcs through a connection matrix. In the connection matrix, the i-nth line represents the weight of the arc connections directed outside of the concept. The i-nth column lists the arcs directed toward , i.e., those affecting .
The conceptual development of FCMs rests on the definition and dynamic of concepts and relationships created by the theory of fuzzy sets (Kosko, 1986). FCM can describe any system using a causality-based model (that indicates positive or negative relationships), which takes fuzzy values and is dynamic (i.e., the effect of a change in one concept/node affects other nodes, which then affect further nodes). This structure establishes the forward and backward propagation of causality (Aguilar, 2005, 2013, 2016). Thus, the concepts and relations can be represented as fuzzy variables (expressed in linguistic terms), such as “Almost Always”, “Always”, “Normally”, “Some (see Figure 2).
The value of a concept depends on its previous iterations, following the equation (1):
Cm(i+1) stands for the value of the concept in the next iteration after the iteration i, N indicates the number of concepts, wm,k represents the value of the causal relationship between the concept Ck and the concept Cm, and S(y) is a function used to normalize the value of the concept.
Figure 2. Example of an FCM (taken from Sánchez et al., 2019).
MFCM is an extension of the FCM. It is a FCM with several layers where each layer represents a set of concepts that define a specific domain of a system. To construct a MFCM, the previous equation for calculating the current status of the concepts of a FCM is modified, to describe the relationships between different layers (Aguilar, 2016):
Where F(p) is the input function generated by the relationships among different layers, and p is the set of concepts of the other layers that impact this concept. Thus, the update function of the concepts has two parts. The first part, the classic, calculates the value of concept in iteration based on the values of concepts in the previous iteration . All these concepts belong to the same layer where the “m” concept belongs. The second part is the result of the causal relationship between the concepts in different levels of the MFCM.
Terán, O. & Aguilar, J. (2022) Towards contextualized social simulation: Complementary use of Multi-Fuzzy Cognitive Maps and MABS. Review of Artificial Societies and Social Simulation, 25th May 2022. https://rofasss.org/2022/05/25/MFCM-MABS
By Peer-Olaf Siebers, in collaboration with Kwabena Amponsah, James Hey, Edmund Chattoe-Brown and Melania Borit
Motivation
1.1: Some time ago, I had several discussions with my PhD students Kwabena Amponsah and James Hey (we are all computer scientists, with a research interest in multi-agent systems) on the topic of qualitative vs. quantitative data in the context of Agent-Based Social Simulation (ABSS). Our original goal was to better understand the role of qualitative vs. quantitative data in the life cycle of an ABSS study. But as you will see later, we conquered more ground during our discussions.
1.2: The trigger for these discussions came from numerous earlier discussions within the RAT task force (Sebastian Achter, Melania Borit, Edmund Chattoe-Brown, and Peer-Olaf Siebers) on the topic, while we were developing the Rigour and Transparency – Reporting Standard (RAT-RS). The RAT-RS is a tool to improve the documentation of data use in Agent-Based Modelling (Achter et al 2022). During our RAT-RS discussions we made the observation that when using the terms “qualitative data” and “quantitative data” in different phases of the ABM simulation study life cycle these could be interpreted in different ways, and we felt difficult to clearly state the definition/role of these different types of data in the different contexts that the individual phases within the life cycle represent. This was aggravated by the competing understandings of the terminology within different domains (from social and natural sciences) that form the field of social simulation.
1.3: As the ABSS community is a multi-disciplinary one, often doing interdisciplinary research, we thought that we should share the outcome of our discussions with the community. To demonstrate the different views that exist within the topic area, we ask some of our friends from the social simulation community to comment on our philosophical discussions. And we were lucky enough to get our RAT-RS colleagues Edmund Chattoe-Brown and Melania Borit on board who provided critical feedback and their own view of things. In the following we provide a summary of the overall discussion Each of the following paragraph contains summaries of the initial discussion outcomes, representing the computer scientists’ views, followed by some thoughts provided by our two friends from the social simulation community (Borit’s in {} brackets and italicand Chattoe-Brown’s in [] brackets and bold), both commenting on the initial discussion outcomes of the computer scientists. To see the diverse backgrounds of all the contributors and perhaps to better understand their way of thinking and their arguments, I have added some short biographies of all contributors at the end of this Research Note. To support further (public) discussions I have numbered the individual paragraphs to make it easier to refer back to them.
Terminology
2.1: As a starting point for our discussions I searched the internet for some terminology related to the topic of “data”. Following is a list of initial definitions of relevant terms [1]. First, the terms qualitative data and quantitative data, as defined by the Australian Bureau of Statistics: “Qualitative data are measures of ‘types’ and may be represented by a name, symbol, or a number code. They are data about categorical variables (e.g. what type). Quantitative data are measures of values or counts and are expressed as numbers. They are data about numeric variables (e.g. how many; how much; or how often).” (Australian Bureau of Statistics 2022) [Maybe don’t let a statistics unit define qualitative research? This has a topic that is very alien to us but argues “properly” about the role of different methods (Helitzer-Allen and Kendall 1992). “Proper” qualitative researchers would fiercely dispute this. It is “quantitative imperialism”.].
2.2: What might also help for this discussion is to better understand the terms qualitative data analysis and quantitative data analysis. Qualitative data analysis refers to “the processes and procedures that are used to analyse the data and provide some level of explanation, understanding, or interpretation” (Skinner et al 2021). [This is a much less contentious claim for qualitative data – and makes the discussion of the Australian Bureau of Statistics look like a distraction but a really “low grade” source in peer review terms. A very good one is Strauss (1987).] These methods include content analysis, narrative analysis, discourse analysis, framework analysis, and grounded theory and the goal is to identify common patterns. {These data analysis methods connect to different types of qualitative research: phenomenology, ethnography, narrative inquiry, case study research, or grounded theory. The goal of such research is not always to identify patterns – see (Miles and Huberman 1994): e.g., making metaphors, seeing plausibility, making contrasts/comparisons.}[In my opinion some of these alleged methods are just empire building or hot air. Do you actually need them for your argument?] These types of analysis must therefore use qualitative inputs, broadening the definition to include raw text, discourse and conceptual frameworks.
2.3 When it comes to quantitative data analysis “you are expected to turn raw numbers into meaningful data through the application of rational and critical thinking. Quantitative data analysis may include the calculation of frequencies of variables and differences between variables.” (Business Research Methodology 2022) {One does the same in qualitative data analysis – turns raw words (or pictures etc.) into meaningful data through the application of interpretation based on rational and critical thinking. In quantitative data analysis you usually apply mathematical/statistical models to analyse the data.}. While the output of quantitative data analysis can be used directly as input to a simulation model, the output of qualitative data analysis still needs to be translated into behavioural rules to be useful (either manually or through machine learning algorithms). {What is meant by “translated” in this specific context? Do we need this kind of translation only for qualitative data or also for quantitative data? Is there a difference between translation methods of qualitative and quantitative data?} [That seems pretty contentious too. It is what is often done, true, but I don’t think it is a logical requirement. I guess you could train a neural net using “cases” or design some other simple “cognitive architecture” from the data. Would this (Becker 1953), for example, best be modelled as “rules” or as some kind of adaptive process? But of course you have to be careful that “rule” is not defined so broadly that everything is one or it is true by definition. I wonder what the “rules” are in this: Chattoe-Brown (2009).]
2.4: Finally, let’s have a quick look at the difference between “data” and “evidence”. For this, we found the following distinction by Wilkinson (2022) helpful: “… whilst data can exist on its own, even though it is essentially meaningless without context, evidence, on the other hand, has to be evidence of or for something. Evidence only exists when there is an opinion, a viewpoint or an argument.”
Hypothesis
3.1: The RAT-RS divides the simulation life cycle into five phases, in terms of data use: model aim and context, conceptualisation, operationalisation, experimentation, and evaluation (Siebers et al 2019). We started our discussion by considering the following hypothesis: The outcome of qualitative data analysis is only useful for the purpose of conceptualisation and as a basis for producing quantitative data. It does not have any other roles within the ABM simulation study life cycle. {Maybe this hypothesis in itself has to be discussed. Is it so that you use only numbers in the operationalisation phase? One can write NetLogo code directly from qualitative data, without numbers.} [Is this inevitable given the way ABM works? Agents have agency and therefore can decide to do things (and we can only access this by talking to them, probably “open ended”). A statistical pattern – time series or correlation – has no agency and therefore cannot be accessed “qualitatively” – though we also sometimes mean by “qualitative” eyeballing two time series rather than using some formal measure of tracking. I guess that use would >>not<< be relevant here.]
Discussion
4.1: One could argue that qualitative data analysis provides causes for behaviour (and indications about their importance (ranking); perhaps also the likelihood of occurrence) as well as key themes that are important to be considered in a model. All sounds very useful for the conceptual modelling phase. The difficulty might be to model the impact (how do we know we model it correctly and at the right level), if that is not easily translatable into a quantitative value but requires some more (behavioural) mechanistic structures to represent the impact of behaviours. [And, of course, there is a debate in psychology (with some evidence on both sides) about the extent to which people are able to give subjective accounts we can trust (see Hastorf and Cantril (1954).] This might also provide issues when it comes to calibration – how does one calibrate qualitative data? {Triangulation.} One random idea we had was that perhaps fuzzy logic could help with this. More brainstorming and internet research is required to confirm that this idea is feasible and useful. [A more challenging example might be ethnographic observation of a “neighbourhood” in understanding crime. This is not about accessing the cognitive content of agents but may well still contribute to a well specified model. It is interesting how many famous models – Schelling, Zaller-Deffuant – actually have no “real” environment.]
4.2: One could also argue that what starts (or what we refer to initially) as qualitative data always ends up as quantitative data, as whatever comes out of the computer are numbers. {This is not necessarily true. Check the work on qualitative outputs using Grounded Theory by Neumann (2015).} Of course this is a question related to the conceptual viewpoint. [Not convinced. It sounds like all sociology is actually physics because all people are really atoms. Formally, everything in computers is numbers because it has to be but that isn’t the same as saying that data structures or whatever don’t constitute a usable and coherent level of description: We “meet” and “his” opinion changes “mine” and vice versa. Somewhere, that is all binary but you can read the higher level code that you can understand as “social influence” (whatever you may think of the assumptions). Be clear whether this (like the “rules” claim) is a matter of definition – in which case it may not be useful (even if people are atoms we have no idea of how to solve the “atomic physics” behind the Prisoner’s Dilemma) or an empirical one (in which case some models may just prove it false). This (Beltratti et al 1996) contains no “rules” and no “numbers” (except in the trivial sense that all programming does).]
4.3: Also, an algorithm is expressed in code and can only be processed numerically, so it can only deliver quantitative data as output. These can perhaps be translated into qualitative concepts later. A way of doing this via the use of grounded theory is proposed in Neumann and Lotzmann (2016). {This refers to the same idea as my previous comment.} [Maybe it is “safest” to discuss this with rules because everyone knows those are used in ABM. Would it make sense to describe the outcome of a non trivial set of rules – accessed for example like this: Gladwin (1989) – as either “quantitative” or “numbers?”]
4.4: But is it true that data delivered as output is always quantitative? Let’s consider, for example, a consumer marketing scenario, where we define stereotypes (shopping enthusiast; solution demander; service seeker; disinterested shopper; internet shopper) that can change over time during a simulation run (Siebers et al 2010). These stereotypes are defined by likelihoods (likelihood to buy, wait, ask for help, and ask for refund). So, during a simulation run an agent could change its stereotype (e.g. from shopping enthusiast to disinterested shopper), influenced by the opinion of others and their own previous experience. So, at the beginning of the simulation run the agent can have a different stereotype compared to the end. Of course we could enumerate the five different stereotypes, and claim that the outcome is numeric, but the meaning of the outcome would be something qualitative – the stereotype related to that number. To me this would be a qualitative outcome, while the number of people that change from one stereotype to another would be a quantitative outcome. They would come in a tandem. {So, maybe the problem is that we don’t yet have the right ways of expressing or visualising qualitative output?} [This is an interesting and grounded example but could it be easily knocked down because everything is “hard coded” and therefore quantifiable? You may go from one shopper type to another – and what happens depends on other assumptions about social influence and so on – but you can’t “invent” your own type. Compare something like El Farol (Arthur 1994) where agents arguably really can “invent” unique strategies (though I grant these are limited to being expressed in a specified “grammar”).]
4.5: In order to define someone’s stereotype we would use numerical values (likelihood = proportion). However, stereotypes refer to nominal data (which refers to data that is used for naming or labelling variables, without any quantitative value). The stereotype itself would be nominal, while the way one would derive the stereotype would be numerical. Figure 1 illustrates a case in which the agent moves from the disinterested stereotype to the enthusiast stereotype. [Is there a potential confusion here between how you tell an agent is a type – parameters in the code just say so – and how you say a real person is a type? Everything you say about the code still sounds “quantitative” because all the “ingredients” are.]
Figure 1: Enthusiastic and Disinterested agent stereotypes
4.6: Let’s consider a second example, related to the same scenario: The dynamics over time to get from an enthusiastic shopper (perhaps via phases) to a disinterested shopper. This is represented as a graph where the x-axis represents time and the y-axis stereotypes (categorical data). If you want to take a quantitative perspective on the outcome you would look at a specific point in time (state of the system) but to take a qualitative perspective of the outcome, you would look at the pattern that the curve represents over the entire simulation runtime. [Although does this shade into the “eyeballing” sense of qualitative rather than the “built from subjective accounts” sense? Another way to think of this issue is to imagine “experts” as a source of data. We might build an ABM based on an expert perception of say, how a crime gang operates. That would be qualitative but not just individual rules: For example, if someone challenges the boss to a fight and loses they die or leave. This means the boss often has no competent potential successors.]
4.7: So, the inputs (parameters, attributes) to get the outcome are numeric, but the outcome itself in the latter case is not. The outcome only makes sense once it’s put into the qualitative context. And then we could say that the simulation produces some qualitative outputs. So, does the fact that data needs to be seen in a context make it evidence, i.e. do we only have quantitative and qualitative evidence on the output side? [Still worried that you may not be happy equating qualitative interview data with qualitative eyeballing of graphs. Mixes up data collection and analysis? And unlike qualitative interviews you don’t have to eyeball time series. But the argument of qualitative research is you can’t find out some things any other way because, to run a survey say, or an experiment, you already have to have a pretty good grasp of the phenomenon.]
4.8: If one runs a marketing campaign that will increase the number of enthusiastic shoppers. This can be seen as qualitative data as it is descriptive of how the system works rather than providing specific values describing the performance of a system. You could also equally express this algebraic terms which would make it quantitative data. So, it might be useful to categorise quantitative data to make the outcome easier to understand. [I don’t think this argument is definitely wrong – though I think it may be ambiguous about what “qualitative” means – but I think it really needs stripping down and tightening. I’m not completely convinced as a new reader that I’m getting at the nub of the argument. Maybe just one example in detail and not two in passing?]
Outcome
5.1: How we understand things and how the computer processes things are two different things. So, in fact qualitative data is useful for the conceptualisation and for describing experimentation and evaluation output, and needs to be translated into numerical data or algebraic constructs for the operationalisation. Therefore, we can reject our initial hypothesis, as we found more places where qualitative data can be useful. [Yes, and that might form the basis for a “general” definition of qualitative that was not tied to one part of the research process but you would have to be clear that’s what you were aiming at and not just accidentally blurring two different “senses” of qualitative.]
5.2: In the end of the discussion we picked up the idea of using Fuzzy Logic. Could perhaps fuzzy logic be used to describe qualitative output, as it describes a degree of membership to different categories? An interesting paper to look at in this context would be Sugeno and Yasukawa (1993). Also, a random idea that was mentioned is if there is potential in using “fuzzy logic in reverse”, i.e. taking something that is fuzzy, making it crisp for the simulation, and making it fuzzy again for presenting the result. However, we decided to save this topic for another discussion. [Devil will be in the detail. Depends on exactly what assumptions the method makes. Devil’s advocate: What if qualitative research is only needed for specification – not calibration or validation – but it doesn’t follow from this that that use is “really” quantitative? How intellectually unappealing is that situation and why?]
Conclusion
6.1: The purpose of this Research Note is really to stimulate you to think about, talk about, and share your ideas and opinions on the topic! What we present here is a philosophical impromptu discussion of our individual understanding of the topic, rather than a scientific debate that is backed up by literature. We still thought it is worthwhile to share this with you, as you might stumble across similar questions. Also, we don’t think we have found the perfect answers to the questions yet. So we would like to invite you to join the discussion and leave some comments in the chat, stating your point of view on this topic. [Is the danger of discussing these data types “philosophically”? I don’t know if it is realistic to use examples directly from social simulation but for sure examples can be used from social science generally. So here is a “quantitative” argument from quantitative data: “The view that cultural capital is transmitted from parents to their children is strongly supported in the case of pupils’ cultural activities. This component of pupils’ cultural capital varies by social class, but this variation is entirely mediated by parental cultural capital.” (Sullivan 2001). As well as the obvious “numbers” (social class by a generally agreed scheme) there is also a constructed “measure” of cultural capital based on questions like “how many books do you read in a week?” Here is an example of qualitative data from which you might reason: “I might not get into Westbury cos it’s siblings and how far away you live and I haven’t got any siblings there and I live a little way out so I might have to go on a waiting list … I might go to Sutton Boys’ instead cos all my mates are going there.” (excerpt from Reay 2002). As long as this was not just a unique response (but was supported by several other interviews) one would add to one’s “theory” of school choice: 1) Awareness of the impact of the selection system (there is no point in applying here whatever I may want) and 2) The role of networks in choice: This might be the best school for me educationally but I won’t go because I will be lonely.]
Biographies of the authors
Peer-Olaf Siebers is an Assistant Professor at the School of Computer Science, University of Nottingham, UK. His main research interest is the application of Computer Simulation and Artificial Intelligence to study human-centric and coupled human-natural systems. He is a strong advocate of Object-Oriented Agent-Based Social Simulation and is advancing the methodological foundations. It is a novel and highly interdisciplinary research field, involving disciplines like Social Science, Economics, Psychology, Geography, Operations Research, and Computer Science.
Kwabena Amponsah is a Research Software Engineer working for the Digital Research Service, University of Nottingham, UK. He completed his PhD in Computer Science at Nottingham in 2019 by developing a framework for evaluating the impact of communication on performance in large-scale distributed urban simulations.
James Hey is a PhD student at the School of Computer Science, University of Nottingham, UK. In his PhD he investigates the topic of surrogate optimisation for resource intensive agent based simulation of domestic energy retrofit uptake with environmentally conscious agents. James holds a Bachelor degree in Economics as well as a Master degree in Computer Science.
Edmund Chattoe-Brown is a lecturer in Sociology, School of Media, Communication and Sociology, University of Leicester, UK. His career has been interdisciplinary (including Politics, Philosophy, Economics, Artificial Intelligence, Medicine, Law and Anthropology), focusing on the value of research methods (particularly Agent-Based Modelling) in generating warranted social knowledge. His aim has been to make models both more usable generally and particularly more empirical (because the most rigorous social scientists tend to be empirical). The results of his interests have been published in 17 different peer reviewed journals across the sciences to date. He was funded by the project “Towards Realistic Computational Models Of Social Influence Dynamics” (ES/S015159/1) by the ESRC via ORA Round 5.
Melania Borit is an interdisciplinary researcher and the leader of the CRAFT Lab – Knowledge Integration and Blue Futures at UiT The Arctic University of Norway. She has a passion for knowledge integration and a wide range of interconnected research interests: social simulation, agent-based modelling; research methodology; Artificial Intelligence ethics; pedagogy and didactics in higher education, games and game-based learning; culture and fisheries management, seafood traceability; critical futures studies.
References
Achter S, Borit M, Chattoe-Brown E, and Siebers PO (2022) RAT-RS: a reporting standard for improving the documentation of data use in agent-based modelling. International Journal of Social Research Methodology, DOI: 10.1080/13645579.2022.2049511
Chattoe-Brown E (2009) The social transmission of choice: a simulation with applications to hegemonic discourse. Mind & Society, 8(2), pp.193-207. DOI: 10.1007/s11299-009-0060-7
Gladwin CH (1989) Ethnographic Decision Tree Modeling. SAGE Publications.
Hastorf AH and Cantril H (1954) They saw a game; a case study. The Journal of Abnormal and Social Psychology, 49(1), pp.129–134.
Helitzer-Allen DL and Kendall C (1992) Explaining differences between qualitative and quantitative data: a study of chemoprophylaxis during pregnancy. Health Education Quarterly, 19(1), pp.41-54. DOI: 10.1177%2F109019819201900104
Miles MB and Huberman AM (1994) . Qualitative Data Analysis: An Expanded Sourcebook. Sage
Neumann M (2015) Grounded simulation. Journal of Artificial Societies and Social Simulation, 18(1)9. DOI: 10.18564/jasss.2560
Neumann M and Lotzmann U (2016) Simulation and interpretation: a research note on utilizing qualitative research in agent based simulation. International Journal of Swarm Intelligence and Evolutionary Computing 5/1.
Reay D (2002) Shaun’s Story: Troubling discourses of white working-class masculinities. Gender and Education, 14(3), pp.221-234. DOI: 10.1080/0954025022000010695
Siebers PO, Achter S, Palaretti Bernardo C, Borit M, and Chattoe-Brown E (2019) First steps towards RAT: a protocol for documenting data use in the agent-based modeling process (Extended Abstract). Social Simulation Conference 2019 (SSC 2019), 23-27 Sep, Mainz, Germany.
Siebers PO, Aickelin U, Celia H and Clegg C (2010) Simulating customer experience and word-of-mouth in retail: a case study. Simulation: Transactions of the Society for Modeling and Simulation International, 86(1) pp. 5-30. DOI: 10.1177%2F0037549708101575
Skinner J, Edwards A and Smith AC (2021) Qualitative Research in Sport Management – 2e, p171. Routledge.
Strauss AL (1987). Qualitative Analysis for Social Scientists. Cambridge University Press.
Sugeno M and Yasukawa T (1993) A fuzzy-logic-based approach to qualitative modeling. IEEE Transactions on Fuzzy Systems, 1(1), pp.7-31.
Sullivan A (2001) Cultural capital and educational attainment. Sociology 35(4), pp.893-912. DOI: 10.1017/S0038038501008938
[1] An updated set of the terminology, defined by the RAT task force in 2022, is available as part of the RAT-RS in Achter et al (2022) Appendix A1.
Peer-Olaf Siebers, Kwabena Amponsah, James Hey, Edmund Chattoe-Brown and Melania Borit (2022) Discussions on Qualitative & Quantitative Data in the Context of Agent-Based Social Simulation. Review of Artificial Societies and Social Simulation, 16th May 2022. https://rofasss.org/2022/05/16/Q&Q-data-in-ABM
1Department of Computing Science, Faculty of Science and Technology, Umeå University, frank.dignum@umu.se 2Centre for Policy Modelling, Manchester Metropolitan University, bruce@edmonds.name 3Department of Psychology, University of Limerick, dino.carpentras@gmail.com
In this position paper we argue for the creation of a new ‘field’: Socio-Cognitive Systems. The point of doing this is to highlight the importance of a multi-levelled approach to understanding those phenomena where the cognitive and the social are inextricably intertwined – understanding them together.
What goes on ‘in the head’ and what goes on ‘in society’ are complex questions. Each of these deserves serious study on their own – motivating whole fields to answer them. However, it is becoming increasingly clear that these two questions are deeply related. Humans are fundamentally social beings, and it is likely that many features of their cognition have evolved because they enable them to live within groups (Herrmann et al. 20007). Whilst some of these social features can be studied separately (e.g. in a laboratory), others only become fully manifest within society at large. On the other hand, it is also clear that how society ‘happens’ is complicated and subtle and that these processes are shaped by the nature of our cognition. In other words, what people ‘think’ matters for understanding how society ‘is’ and vice versa. For many reasons, both of these questions are difficult to answer. As a result of these difficulties, many compromises are necessary in order to make progress on them, but each compromise also implies some limitations. The main two types of compromise consist of limiting the analysis to only one of the two (i.e. either cognition or society)[1]. To take but a few examples of this.
Neuro-scientists study what happens between systems of neurones to understand how the brain does things and this is so complex that even relatively small ensembles of neurones are at the limits of scientific understanding.
Psychologists see what can be understood of cognition from the outside, usually in the laboratory so that some of the many dimensions can be controlled and isolated. However, what can be reproduced in a laboratory is a limited part of behaviour that might be displayed in a natural social context.
Economists limit themselves to the study of the (largely monetary) exchange of services/things that could occur under assumptions of individual rationality, which is a model of thinking not based upon empirical data at the individual level. Indeed it is known to contradict a lot of the data and may only be a good approximation for average behaviour under very special circumstances.
Ethnomethodologists will enter a social context and describe in detail the social and individual experience there, but not generalise beyond that and not delve into the cognition of those they observe.
Other social scientists will take a broader view, look at a variety of social evidence, and theorise about aspects of that part of society. They (almost always) do not include individual cognition into account in these and do not seek to integrate the social and the cognitive levels.
Each of these in the different ways separate the internal mechanisms of thought from the wider mechanisms of society or limits its focus to a very specific topic. This is understandable; what each is studying is enough to keep them occupied for many lifetimes. However, this means that each of these has developed their own terms, issues, approaches and techniques which make relating results between fields difficult (as Kuhn, 1962, pointed out).
Figure 1: Schematic representation of the relationship between the individual and society. Individuals’ cognition is shaped by society, at the same time, society is shaped by individuals’ beliefs and behaviour.
This separation of the cognitive and the social may get in the way of understanding many things that we observe. Some phenomena seem to involve a combination of these aspects in a fundamental way – the individual (and its cognition) being part of society as well as society being part of the individual. Some examples of this are as follows (but please note that this is far from an exhaustive list).
Norms. A social norm is a constraint or obligation upon action imposed by society (or perceived as such). One may well be mistaken about a norm (e.g. whether it is ok to casually talk to others at a bus stop), thus it is also a belief – often not told to one explicitly but something one needs to infer from observation. However, for a social norm to hold it also needs to be an observable convention. Decisions to violate social norms require that the norm is an explicit (referable) object in the cognitive model. But the violation also has social consequences. If people react negatively to violations the norm can be reinforced. But if violations are ignored it might lead to a norm disappearing. How new norms come about, or how old ones fade away, is a complex set of interlocking cognitive and social processes. Thus social norms are a phenomena that essentially involves both the social and the cognitive (Conte et al. 2013).
Joint construction of social reality. Many of the constraints on our behaviour come from our perception of social reality. However, we also create this social reality and constantly update it. For example, we can invent a new procedure to select a person as head of department or exit a treaty and thus have different ways of behaving after this change. However, these changes are not unconstrained in themselves. Sometimes the time is “ripe for change”, while at other times resistance is too big for any change to take place (even though a majority of the people involved would like to change). Thus what is socially real for us depends on what people individually believe is real, but this depends in complex ways on what other people believe and their status. And probably even more important: the “strength” of a social structure depends on the use people make of it. E.g. a head of department becomes important if all decisions in the department are deferred to the head. Even though this might not be required by university or law.
Identity. Our (social) identity determines the way other people perceive us (e.g. a sports person, a nerd, a family man) and therefore creates expectations about our behaviour. We can create our identities ourselves and cultivate them, but at the same time, when we have a social identity, we try to live up to it. Thus, it will partially determine our goals and reactions and even our feeling of self-esteem when we live up to our identity or fail to do so. As individuals we (at least sometimes) have a choice as to our desired identity, but in practice, this can only be realised with the consent of society. As a runner I might feel the need to run at least three times a week in order for other people to recognize me as runner. At the same time a person known as a runner might be excused from a meeting if training for an important event. Thus reinforcing the importance of the “runner” identity.
Social practices. The concept already indicates that social practices are about the way people habitually interact and through this interaction shape social structures. Practices like shaking hands when greeting do not always have to be efficient, but they are extremely socially important. For example, different groups, countries and cultures will have different practices when greeting and performing according to the practice shows whether you are part of the in-group or out-group. However, practices can also change based on circumstances and people, as it happened, for example, to the practice of shaking hands during the covid-19 pandemic. Thus, they are flexible and adapting to the context. They are used as flexible mechanisms to efficiently fit interactions in groups, connecting persons and group behaviour.
As a result, this division between cognitive and the social gets in the way not only of theoretical studies, but also in practical applications such as policy making. For example, interventions aimed at encouraging vaccination (such as compulsory vaccination) may reinforce the (social) identity of the vaccine hesitant. However, this risk and its possible consequences for society cannot be properly understood without a clear grasp of the dynamic evolution of social identity.
Computational models and systems provide a way of trying to understand the cognitive and the social together. For computational modellers, there is no particular reason to confine themselves to only the cognitive or only the social because agent-based systems can include both within a single framework. In addition, the computational system is a dynamic model that can represent the interactions of the individuals that connect the cognitive models and the social models. Thus the fact that computational models have a natural way to represent the actions as an integral and defining part of the socio-cognitive system is of prime importance. Given that the actions are an integral part of the model it is well suited to model the dynamics of socio-cognitive systems and track changes at both the social and the cognitive level. Therefore, within such systems we can study how cognitive processes may act to produce social phenomena whilst, at the same time, as how social realities are shaping the cognitive processes. Caarley and Newell (1994) discusses what is necessary at the agent level for sociality, Hofested et al. (2021) talk about how to understand sociality using computational models (including theories of individual action) – we want to understand both together. Thus, we can model the social embeddedness that Granovetter (1985) talked about – going beyond over- or under-socialised representations of human behaviour. It is not that computational models are innately suitable for modelling either the cognitive or the social, but that they can be appropriately structured (e.g. sets of interacting parts bridging micro-, meso- and macro-levels) and include arbitrary levels of complexity. Lots of models that represent the social have entities that stand for the cognitive, but do not explicitly represent much of that detail – similarly much cognitive modelling implies the social in terms of the stimuli and responses of an individual that would be to other social entities, but where these other entities are not explicitly represented or are simplified away.
Socio-Cognitive Systems (SCS) are: those models and systems where both cognitive and social complexity are represented with a meaningful level of processual detail.
A good example of an application where this appeared of the biggest importance was in simulations for the covid-19 crisis. The spread of the corona virus on macro level could be given by an epidemiological model, but the actual spreading depended crucially on the human behaviour that resulted from individuals’ cognitive model of the situation. In Dignum (2021) it was shown how the socio-cognitive system approach was fundamental to obtaining better insights in the effectiveness of a range of covid-19 restrictions.
Formality here is important. Computational systems are formal in the sense that they can be unambiguously passed around (i.e. unlike language, it is not differently re-interpreted by each individual) and operate according to their own precisely specified and explicit rules. This means that the same system can be examined and experimented on by a wider community of researchers. Sometimes, even when the researchers from different fields find it difficult to talk to one another, they can fruitfully cooperate via a computational model (e.g. Lafuerza et al. 2016). Other kinds of formal systems (e.g. logic, maths) are geared towards models that describe an entire system from a birds eye view. Although there are some exceptions like fibred logics Gabbay (1996), these are too abstract to be of good use to model practical situations. The lack of modularity and has been addressed in context logics Giunchiglia, F., & Ghidini, C. (1998). However, the contexts used in this setting are not suitable to generate a more general societal model. It results in most typical mathematical models using a number of agents which is either one, two or infinite (Miller and Page 2007), while important social phenomena happen with a “medium sized” population. What all these formalisms miss is a natural way of specifying the dynamics of the system that is modelled, while having ways to modularly describe individuals and the society resulting from their interactions. Thus, although much of what is represented in Socio-Cognitive Systems is not computational, the lingua franca for talking about them is.
The ‘double complexity’ of combining the cognitive and the social in the same system will bring its own methodological challenges. Such complexity will mean that many socio-cognitive systems will be, themselves, hard to understand or analyse. In the covid-19 simulations, described in (Dignum 2021), a large part of the work consisted of analysing, combining and representing the results in ways that were understandable. As an example, for one scenario 79 pages of graphs were produced showing different relations between potentially relevant variables. New tools and approaches will need to be developed to deal with this. We only have some hints of these, but it seems likely that secondary stages of analysis – understanding the models – will be necessary, resulting in a staged approach to abstraction (Lafuerza et al. 2016). In other words, we will need to model the socio-cognitive systems, maybe in terms of further (but simpler) socio-cognitive systems, but also maybe with a variety of other tools. We do not have a view on this further analysis, but this could include: machine learning, mathematics, logic, network analysis, statistics, and even qualitative approaches such as discourse analysis.
An interesting input for the methodology of designing and analysing socio-cognitive systems is anthropology and specifically ethnographical methods. Again, for the covid-19 simulations the first layer of the simulation was constructed based on “normal day life patterns”. Different types of persons were distinguished that each have their own pattern of living. These patterns interlock and form a fabric of social interactions that overall should satisfy most of the needs of the agents. Thus we calibrate the simulation based on the stories of types of people and their behaviours. Note that doing the same just based on available data of behaviour would not account for the underlying needs and motives of that behaviour and would not be a good basis for simulating changes. The stories that we used looked very similar to the type of reports ethnographers produce about certain communities. Thus further investigating this connection seems worthwhile.
For representing the output of the complex socio-cognitive systems we can also use the analogue of stories. Basically, different stories show the underlying (assumed) causal relations between phenomena that are observed. E.g. seeing an increase in people having lunch with friends can be explained by the fact that a curfew prevents people having dinner with their friends, while they still have a need to socialize. Thus the alternative of going for lunch is chosen more often. One can see that the explaining story uses both social as well as cognitive elements to describe the results. Although in the covid-19 simulations we have created a number of these stories, they were all created by hand after (sometimes weeks) of careful analysis of the results. Thus for this kind of approach to be viable, new tools are required.
Although human society is the archetypal socio-cognitive system, it is not the only one. Both social animals and some artificial systems also come under this category. These may be very different from the human, and in the case of artificial systems completely different. Thus, Socio-Cognitive Systems is not limited to the discussion of observable phenomena, but can include constructed or evolved computational systems, and artificial societies. Examination of these (either theoretically or experimentally) opens up the possibility of finding either contrasts or commonalities between such systems – beyond what happens to exist in the natural world. However, we expect that ideas and theories that were conceived with human socio-cognitive systems in mind might often be an accessible starting point for understanding these other possibilities.
In a way, Socio-Cognitive Systems bring together two different threads in the work of Herbert Simon. Firstly, as in Simon (1948) it seeks to take seriously the complexity of human social behaviour without reducing this to overly simplistic theories of individual behaviour. Secondly, it adopts the approach of explicitly modelling the cognitive in computational models (Newell & Simon 1972). Simon did not bring these together in his lifetime, perhaps due to the limitations and difficulty of deploying the computational tools to do so. Instead, he tried to develop alternative mathematical models of aspects of thought (Simon 1957). However, those models were limited by being mathematical rather than computational.
To conclude, a field of Socio-Cognitive Systems would consider the cognitive and the social in an integrated fashion – understanding them together. We suggest that computational representation or implementation might be necessary to provide concrete reference between the various disciplines that are needed to understand them. We want to encourage research that considers the cognitive and the social in a truly integrated fashion. If by labelling a new field does this it will have achieved its purpose. However, there is the possibility that completely new classes of theory and complexity may be out there to be discovered – phenomena that are denied if either the cognitive or the social are not taken together – a new world of a socio-cognitive systems.
Notes
[1] Some economic models claim to bridge between individual behaviour and macro outcomes, however this is traditionally notional. Many economists admit that their primary cognitive models (varieties of economic rationality) are not valid for individuals but are what people on average do – i.e. this is a macro-level model. In other economic models whole populations are formalised using a single representative agent. Recently, there are some agent-based economic models emerging, but often limited to agree with traditional models.
Acknowledgements
Bruce Edmonds is supported as part of the ESRC-funded, UK part of the “ToRealSim” project, grant number ES/S015159/1.
References
Carley, K., & Newell, A. (1994). The nature of the social agent. Journal of mathematical sociology, 19(4): 221-262. DOI: 10.1080/0022250X.1994.9990145
Conte R., Andrighetto G. and Campennì M. (eds) (2013) Minding Norms – Mechanisms and dynamics of social order in agent societies. Oxford University Press, Oxford.
Dignum, F. (ed.) (2021) Social Simulation for a Crisis; Results and Lessons from Simulating the COVID-19 Crisis. Springer.
Herrmann E., Call J, Hernández-Lloreda MV, Hare B, Tomasello M (2007) Humans have evolved specialized skills of social cognition: The cultural intelligence hypothesis. Science317(5843): 1360-1366. DOI: 10.1126/science.1146282
Hofstede, G.J, Frantz, C., Hoey, J., Scholz, G. and Schröder, T. (2021) Artificial Sociality Manifesto. Review of Artificial Societies and Social Simulation, 8th Apr 2021. https://rofasss.org/2021/04/08/artsocmanif/
Gabbay, D. M. (1996). Fibred Semantics and the Weaving of Logics Part 1: Modal and Intuitionistic Logics. The Journal of Symbolic Logic, 61(4), 1057–1120.
Ghidini, C., & Giunchiglia, F. (2001). Local models semantics, or contextual reasoning= locality+ compatibility. Artificial intelligence, 127(2), 221-259. DOI: 10.1016/S0004-3702(01)00064-9
Granovetter, M. (1985) Economic action and social structure: The problem of embeddedness. American Journal of Sociology91(3): 481-510. DOI: 10.1086/228311
Kuhn, T,S, (1962) The structure of scientific revolutions. University of Chicago Press, Chicago
Miller, J. H., Page, S. E., & Page, S. (2009). Complex adaptive systems. Princeton university press.
Newell A, Simon H.A. (1972) Human problem solving. Prentice Hall, Englewood Cliffs, NJ
Simon, H.A. (1948) Administrative behaviour: A study of the decision making processes in administrative organisation. Macmillan, New York
Simon, H.A. (1957) Models of Man: Social and rational. John Wiley, New York
Dignum, F., Edmonds, B. and Carpentras, D. (2022) Socio-Cognitive Systems – A Position Statement. Review of Artificial Societies and Social Simulation, 2nd Apr 2022. https://rofasss.org/2022/04/02/scs
The social simulation literature has called on its proponents to enhance the quality and realism of their contributions through systematic validation and calibration (Flache et al., 2017). Model validation typically refers to assessments of how well the predictions of their agent-based models (ABMs) map onto empirically observed patterns or relationships. Calibration, on the other hand, is the process of enhancing the realism of the model by parametrizing it based on empirical data (Boero & Squazzoni, 2005). We would expect that presenting a validated or calibrated model serves as a signal of model quality, and would thus be a desirable characteristic of a paper describing an ABM.
In a recent contribution to RofASSS, Edmund Chattoe-Brown provocatively argued that model validation does not bear fruit for researchers interested in boosting their citations. In a sample of articles from JASSS published on opinion dynamics he observed that “the sample clearly divides into non-validated research with more citations and validated research with fewer” (Chattoe-Brown, 2022). Well-aware of the bias and limitations of the sample at hand, Chattoe-Brown calls on refutation of his hypothesis. An analysis of the corpus of articles in Web of Science, presented here, could serve that goal.
To test whether there exists an effect of model calibration and/or validation on the citation counts of papers, I compare citation counts of a larger number of original research articles on agent-based models published in the literature. I extracted 11,807 entries from Web of Science by searching for items that contained the phrases “agent-based model”, “agent-based simulation” or “agent-based computational model” in its abstract.[1] I then labeled all items that mention “validate” in its abstract as validated ABMs and those that mention “calibrate” as calibrated ABMs. This measure if rather crude, of course, as descriptions containing phrases like “we calibrated our model” or “others should calibrate our model” are both labeled as calibrated models. However, if mentioning that future research should calibrate or validate the model is not related to citations counts (which I would argue it indeed is not), then this inaccuracy does not introduce bias.
The shares of entries that mention calibration or validation are somewhat small. Overall, just 5.62% of entries mention validation, 3.21% report a calibrated model and 0.65% fall in both categories. The large sample size, however, will still enable the execution of proper statistical analysis and hypothesis testing.
How are mentions of calibration and validation in the abstract related to citation counts at face value? Bivariate analyses show only minor differences, as revealed in Figure 1. In fact, the distribution of citations for validated and non-validated ABMs (panel A) is remarkably similar. Wilcoxon tests with continuity correction—the nonparametric version of the simple t test—corroborate their similarity (W = 3,749,512, p = 0.555). The differences in citations between calibrated and non-calibrated models appear, albeit still small, more pronounced. Calibrated ABMs are cited slightly more often (panel B), as also supported by a bivariate test (W = 1,910,772, p < 0.001).
Figure 1. Distributions of number of citations of all the entries in the dataset for validated (panel A) and calibrated (panel B) ABMs and their averages with standard errors over years (panels C and D)
Age of the paper might be a more important determinant of citation counts, as panels C and D of Figure 1 suggest. Clearly, the age of a paper should be important here, because older papers have had much more opportunity to get cited. In particular, papers younger than 10 years seem to not have matured enough for its citation rates to catch up to older articles. When comparing the citation counts of purely theoretical models with calibrated and validated versions, this covariate should not be missed, because the latter two are typically much younger. In other words, the positive relationship between model calibration/validation and citation counts could be hidden in the bivariate analysis, as model calibration and validation are recent trends in ABM research.
I run a Poisson regression on the number of citations as explained by whether they are validated and calibrated (simultaneously) and whether they are both. The age of the paper is taken into account, as well as the number of references that the paper uses itself (controlling for reciprocity and literature embeddedness, one might say). Finally, the fields in which the papers have been published, as registered by Web of Science, have been added to account for potential differences between fields that explains both citation counts and conventions about model calibration and validation.
Table 1 presents the results from the four models with just the main effects of validation and calibration (model 1), the interaction of validation and calibration (model 2) and the full model with control variables (model 3).
Table 1. Poisson regression on the number of citations
# Citations
(1)
(2)
(3)
Validated
-0.217***
-0.298***
-0.094***
(0.012)
(0.014)
(0.014)
Calibrated
0.171***
0.064***
0.076***
(0.014)
(0.016)
(0.016)
Validated x Calibrated
0.575***
0.244***
(0.034)
(0.034)
Age
0.154***
(0.0005)
Cited references
0.013***
(0.0001)
Field included
No
No
Yes
Constant
2.553***
2.556***
0.337**
(0.003)
(0.003)
(0.164)
Observations
11,807
11,807
11,807
AIC
451,560
451,291
301,639
Note:
*p<0.1; **p<0.05; ***p<0.01
The results from the analyses clearly suggest a negative effect of model validation and a positive effect of model calibration on the likelihood of being cited. The hypothesis that was so “badly in need of refutation” (Chattoe-Brown, 2022) will remain unrefuted for now. The effect does turn positive, however, when the abstract makes mention of calibration as well. In both the controlled (model 3) and uncontrolled (model 2) analyses, combining the effects of validation and calibration yields a positive coefficient overall.[2]
The controls in model 3 substantially affect the estimates from the three main factors of interest, while remaining in expected directions themselves. The age of a paper indeed helps its citation count, and so does the number of papers the item cites itself. The fields, furthermore, take away from the main effects somewhat, too, but not to a problematic degree. In an additional analysis, I have looked at the relationship between the fields and whether they are more likely to publish calibrated or validated models and found no substantial relationships. Citation counts will differ between fields, however. The papers in our sample are more often cited in, for example, hematology, emergency medicine and thermodynamics. The ABMs in the sample coming from toxicology, dermatology and religion are on the unlucky side of the equation, receiving less citations on average. Finally, I have also looked at papers published in JASSS specifically, due to the interest of Chattoe-Brown and the nature of this outlet. Surprisingly, the same analyses run on the subsample of these papers (N=376) showed a negative relationship between citation counts and model calibration/validation. Does the JASSS readership reveal its taste for artificial societies?
In sum, I find support for the hypothesis of Chattoe-Brown (2022) on the negative relationship between model validation and citations counts for papers presenting ABMs. If you want to be cited, you should not validate your ABM. Calibrated ABMs, on the other hand, are more likely to receive citations. What is more, ABMs that were both calibrated and validated are most the most successful papers in the sample. All conclusions were drawn considering (i.e. controlling for) the effects of age of the paper, the number of papers the paper cited itself, and (citation conventions in) the field in which it was published.
While the patterns explored in this and Chattoe-Brown’s recent contribution are interesting, or even puzzling, they should not distract from the goal of moving towards realistic agent-based simulations of social systems. In my opinion, models that combine rigorous theory with strong empirical foundations are instrumental to the creation of meaningful and purposeful agent-based models. Perhaps the results presented here should just be taken as another sign that citation counts are a weak signal of academic merit at best.
Data, code and supplementary analyses
All data and code used for this analysis, as well as the results from the supplementary analyses described in the text, are available here: https://osf.io/x9r7j/
Notes
[1] Note that the hyphen between “agent” and “based” does not affect the retrieved corpus. Both contributions that mention “agent based” and “agent-based” were retrieved.
[2] A small caveat to the analysis of the interaction effect is that the marginal improvement of model 2 upon model 1 is rather small (AIC difference of 269). This is likely (partially) due to the small number of papers that mention both calibration and validation (N=77).
Acknowledgements
Marijn Keijzer acknowledges IAST funding from the French National Research Agency (ANR) under the Investments for the Future (Investissements d’Avenir) program, grant ANR-17-EURE-0010.
References
Boero, R., & Squazzoni, F. (2005). Does empirical embeddedness matter? Methodological issues on agent-based models for analytical social science. Journal of Artificial Societies and Social Simulation, 8(4), 1–31. https://www.jasss.org/8/4/6.html
Chattoe-Brown, E. (2022) If You Want To Be Cited, Don’t Validate Your Agent-Based Model: A Tentative Hypothesis Badly In Need of Refutation. Review of Artificial Societies and Social Simulation, 1st Feb 2022. https://rofasss.org/2022/02/01/citing-od-models
Flache, A., Mäs, M., Feliciani, T., Chattoe-Brown, E., Deffuant, G., Huet, S., & Lorenz, J. (2017). Models of social influence: towards the next frontiers. Journal of Artificial Societies and Social Simulation, 20(4). https://doi.org/10.18564/jasss.3521
Keijzer, M. (2022) If you want to be cited, calibrate your agent-based model: Reply to Chattoe-Brown. Review of Artificial Societies and Social Simulation, 9th Mar 2022. https://rofasss.org/2022/03/09/Keijzer-reply-to-Chattoe-Brown
A model[1] is basically composed of two parts (Zeigler 1976, Wartofsky 1979):
A set of entities (such as mathematical equations, logical rules, computer code etc.) which can be used to make some inferences as to the consequences of that set (usually in conjunction with some data and parameter values)
A mapping from this set to what it aims to represent – what the bits mean
Whilst a lot of attention has been paid to the internal rigour of the set of entities and the inferences that are made from them (1), the mapping to what that represents (2) has often been left as implicit or incompletely described – sometimes only indicated by the labels given to its parts. The result is a model that vaguely relates to its target, suggesting its properties analogically. There is not a well-defined way that the model is to be applied to anything observed, but a new map is invented each time it is used to think about a particular case. I call this way of modelling “Suggestivism”, because the model “suggests” things about what is being modelled.
This is partly a recapitulation of Popper’s critique of vague theories in his book “The Poverty of Historicism” (1957). He characterised such theories as “irrefutable”, because whatever the facts, these theories could be made to fit them. Irrefutability is an indicator of a lack of precise mapping to reality – such vagueness makes refutation very hard. However, it is only an indicator; there may be other reasons than vagueness for it not being possible to test a theory – it is their disconnection from well-defined empirical reference that is the issue here.
Some might go as far as suggesting that any model or theory that is not refutable is “unscientific”, but this goes too far, implying a very restricted definition of what ‘science’ is. We need analogies to think about what we are doing and to gain insight into what we are studying, e.g. (Hartman 1997) – for humans they are unavoidable, ‘baked’ into the way language works (Lakoff 1987). A model might make a set of ideas clear and help map out the consequences of a set of assumptions/structures/processes. Many of these suggestivist models relate to a set of ideas and it is the ideas that relate to what is observed (albeit informally) (Edmonds 2001). However, such models do not capture anything reliable about what they refer to, and in that sense are not part of the set of the established statements and theories that is at the core of science (Arnold 2014).
The dangers of suggestivist modelling
As above, there are valid uses of abstract or theoretical modelling where this is explicitly acknowledged and where no conclusions about observed phenomena are made. So what are the dangers of suggestivist modelling – why am I making such a fuss about it?
Firstly, that people often seem to confuse a model as an analogy – a way of thinking about stuff – and a model that tells us reliably about what we are studying. Thus they give undue weight to the analyses of abstract models that are, in fact, just thought experiments. Making models is a very intimate way of theorising – one spends an extended period of time interacting with one’s model: developing, checking, analysing etc. The result is a particularly strong version of “Kuhnian Spectacles” (Kuhn 1962) causing us to see the world though our model for weeks after. Under this strong influence it is natural to confuse what we can reliably infer about the world and how we are currently perceiving/thinking about it. Good scientists should then pause and wait for this effect to wear off so that they can effectively critique what they have done, its limitations and what its implications are. However, often in the rush to get their work out, modellers often do not do this, resulting in a sloppy set of suggestive interpretations of their modelling.
Secondly, empirical modelling is hard. It is far easier (and, frankly, more fun) to play with non-empirical models. A scientific culture that treats suggestivist modelling as substantial progress and significantly rewards modellers that do it, will effectively divert a lot of modelling effort in this direction. Chattoe-Brown (2018) displayed evidence of this in his survey of opinion dynamics models – abstract, suggestivist modelling got far more reward (in terms of citations) than those that tried to relate their model to empirical data in a direct manner. Abstract modelling has a role in science, but if it is easier and more rewarding then the field will become unbalanced. It may give the impression of progress but not deliver on this impression. In a more mature science, researchers working on measurement methods (steps from observation to models) and collecting good data are as important as the theorists (Moss 1998).
Thirdly, it is hard to judge suggestivist models. Given their connection to the modelling target is vague there cannot be any decisive test of its success. Good modellers should declare the exact purpose of their model, e.g. that is analogical or merely exploring the consequences of theory (Edmonds et al. 2019), but then accept the consequences of this choice – namely, that it excludes making conclusions about the observed world. If it is for a theoretical exploration then the comprehensiveness of the exploration, the scope of the exploration and the applicability of the model can be judged, but if the model is analogical or illustrative then this is harder. Whilst one model may suggest X, another may suggest the opposite. It is quite easy to fix a model to get the outcomes one wants. Clearly, if a model makes startling suggestions – illustrating totally new ideas or making a counter-example to widely held assumptions – then this helps science by widening the pool of theories or hypotheses that are considered. However most suggestivist modelling does not do this.
Fourthly, their sheer flexibility of as to application causes problems – if one works hard enough one can invent mappings to a wide range of cases, the limits are only those of our imagination. In effect, having a vague mapping from model to what it models adds in huge flexibility in a similar way to having a large number of free (non-empirical) parameters. This flexibility gives an impression of generality, and many desire simple and general models for complex phenomena. However, this is illusory because a different mapping is needed for each case, to make it apply. Given the above (1)+(2) definition of a model this means that, in fact, it is a different model for each case – what a model refers to, is part of the model. The same flexibility makes such models impossible to refute, since one can just adjust the mapping to save them. The apparent generality and lack of refutation means that such models hang around in the literature, due to their surface attractiveness.
Finally, these kinds of model are hugely influential beyond the community of modellers to the wider public including policy actors. Narratives that start in abstract models make their way out and can be very influential (Vranckx 1999). Despite the lack of rigorous mapping from model to reality, suggestivist models look impressive, look scientific. For example, very abstract models from the Neo-Classical ‘Chicago School’ of economists supported narratives about the optimal efficiency of markets, leading to a reluctance to regulate them (Krugman 2009). A lack of regulation seemed to be one of the factors behind the 2007/8 economic crash (Baily et al 2008). Modellers may understand that other modellers get over-enthusiastic and over-interpret their models, but others may not. It is the duty of modellers to give an accurate impression of the reliability of any modelling results and not to over-hype them.
How to recognise a suggestivist model
It can be hard to detangle how empirically vague a model is, because many descriptions about modelling work do not focus on making the mapping to what it represents precise. The reasons for this are various, for example: the modeller might be conflating reality and what is in the model in their minds, the researcher is new to modelling and has not really decided what the purpose of their model is, the modeller might be over-keen to establish the importance of their work and so is hyping the motivation and conclusions, they might simply not got around to thinking enough about the relationship between their model and what it might represent, or they might not have bothered to make the relationship explicit in their description. Whatever the reason the reader of any description of such work is often left with an archaeological problem: trying to unearth what the relationship might be, based on indirect clues only. The only way to know for certain is to take a case one knows about and try and apply the model to it, but this is a time consuming process and relies upon having a case with suitable data available. However, there are some indicators, albeit fallible ones, including the following.
A relatively simple model is interpreted as explaining a wide range of observed, complex phenomena
No data from an observed case study is compared to data from the model (often no data is brought in at all, merely abstract observations) – despite this, conclusions about some observed phenomena are made
The purpose of the model is not explicitly declared
The language of the paper seems to conflate talking about the model with what is being modelled
In the paper there are sudden abstraction ‘jumps’ between the motivation and the description of the model and back again to the interpretation of the results in terms of that motivation. The abstraction jumps involved are large and justified by some a priori theory or modelling precedents rather than evidence.
How to avoid suggestivist modelling
How to avoid the dangers of suggestivist modelling should be clear from the above discussion, but I will make them explicit here.
Be clear about the model purpose – that is does the model aim to achieve, which indicates how it should be judged by others (Edmonds et al 2019)
Do not make any conclusions about the real world if you have not related the model to any data
Do not make any policy conclusions – things that might affect other people’s lives – without at least some independent validation of the model outcomes
Document how a model relates (or should relate) to data, the nature of that data and maybe even the process whereby that data should be obtained (Achter et al 2019)
Be explicit as possible about what kinds of phenomena the model applies to – the limits of its scope
Keep the language about the model and what is being modelled distinct – for any statement it should be clear whether it is talking about the model or what it models (Edmonds 2020)
Highlight any bold assumptions in the specification of the model or describe what empirical foundation there is for them – be honest about these
Conclusion
Models can serve many different purposes (Epstein 2008). This is fine as long as the purpose of models are always made clear, and model results are not interpreted further than their established purpose allows. Research which gives the impression that analogical, illustrative or theoretical modelling can tell us anything reliable about observed complex phenomena is not only sloppy science, but can have a deleterious impact – giving an impression of progress whilst diverting attention from empirically reliable work. Like a bad investment: if it looks too good and too easy to be true, it probably isn’t.
Notes
[1] We often use the word “model” in a lazy way to indicate (1) rather than (1)+(2) in this definition, but a set of entities without any meaning or mapping to anything else is not a model, as it does not represent anything. For example, a random set of equations or program instructions does not make a model.
Acknowledgements
Bruce Edmonds is supported as part of the ESRC-funded, UK part of the “ToRealSim” project, grant number ES/S015159/1.
References
Achter, S., Borit, M., Chattoe-Brown, E., Palaretti, C. & Siebers, P.-O. (2019) Cherchez Le RAT: A Proposed Plan for Augmenting Rigour and Transparency of Data Use in ABM. Review of Artificial Societies and Social Simulation, 4th June 2019. https://rofasss.org/2019/06/04/rat/
Arnold, E. (2014). What’s wrong with social simulations?. The Monist, 97(3), 359-377. DOI:10.5840/monist201497323
Chattoe-Brown, E. (2018) What is the earliest example of a social science simulation (that is nonetheless arguably an ABM) and shows real and simulated data in the same figure or table? Review of Artificial Societies and Social Simulation, 11th June 2018. https://rofasss.org/2018/06/11/ecb/
Edmonds, B. (2001) The Use of Models – making MABS actually work. In. Moss, S. and Davidsson, P. (eds.), Multi Agent Based Simulation, Lecture Notes in Artificial Intelligence, 1979:15-32. http://cfpm.org/cpmrep74.html
Edmonds, B. (2020) Basic Modelling Hygiene – keep descriptions about models and what they model clearly distinct. Review of Artificial Societies and Social Simulation, 22nd May 2020. https://rofasss.org/2020/05/22/modelling-hygiene/
Edmonds, B., le Page, C., Bithell, M., Chattoe-Brown, E., Grimm, V., Meyer, R., Montañola-Sales, C., Ormerod, P., Root H. & Squazzoni. F. (2019) Different Modelling Purposes. Journal of Artificial Societies and Social Simulation, 22(3):6. http://jasss.soc.surrey.ac.uk/22/3/6.html.
Hartmann, S. (1997): Modelling and the Aims of Science. In: Weingartner, P. et al (ed.) : The Role of Pragmatics in Contemporary Philosophy: Contributions of the Austrian Ludwig Wittgenstein Society. Vol. 5. Wien und Kirchberg: Digi-Buch. pp. 380-385. https://epub.ub.uni-muenchen.de/25393/
Kuhn, T.S. (1962) The Structure of Scientific Revolutions. Chicago: University of Chicago Press.
Lakoff, G. (1987) Women, fire, and dangerous things. University of Chicago Press, Chicago.
Morgan, M. S., & Morrison, M. (1999). Models as mediators. Cambridge: Cambridge University Press.
Moss, S. (1998) Social Simulation Models and Reality: Three Approaches. Centre for Policy Modelling Discussion Paper: CPM-98-35, http://cfpm.org/cpmrep35.html
Popper, K. (1957). The poverty of historicism. Routledge.
Vranckx, An. (1999) Science, Fiction & the Appeal of Complexity. In Aerts, Diederik, Serge Gutwirth, Sonja Smets, and Luk Van Langehove, (eds.) Science, Technology, and Social Change: The Orange Book of “Einstein Meets Magritte.” Brussels: Vrije Universiteit Brussel; Dordrecht: Kluwer., pp. 283–301.
Wartofsky, M. W. (1979). The model muddle: Proposals for an immodest realism. In Models (pp. 1-11). Springer, Dordrecht.
Zeigler, B. P. (1976). Theory of Modeling and Simulation. Wiley Interscience, New York.
Edmonds, B. (2022) The Poverty of Suggestivism – the dangers of "suggests that" modelling. Review of Artificial Societies and Social Simulation, 28th Feb 2022. https://rofasss.org/2022/02/28/poverty-suggestivism
As part of a previous research project, I collected a sample of the Opinion Dynamics (hereafter OD) models published in JASSS that were most highly cited in JASSS. The idea here was to understand what styles of OD research were most influential in the journal. In the top 50 on 19.10.21 there were eight such articles. Five were self-contained modelling exercises (Hegselmann and Krause 2002, 58 citations, Deffuant et al. 2002, 35 citations, Salzarulo 2006, 13 citations, Deffuant 2006, 13 citations and Urbig et al. 2008, 9 citations), two were overviews of OD modelling (Flache et al. 2017, 13 citations and Sobkowicz 2009, 10 citations) and one included an OD example in an article mainly discussing the merits of cellular automata modelling (Hegselmann and Flache 1998, 12 citations). In order to get in to the top 50 on that date you had to achieve at least 7 citations. In parallel, I have been trying to identify Agent-Based Models that are validated (undergo direct comparison of real and equivalent simulated data). Based on an earlier bibliography (Chattoe-Brown 2020) which I extended to the end of 2021 for JASSS and articles which were described as validated in the highly cited articles listed above, I managed to construct a small and unsystematic sample of validated OD models. (Part of the problem with a systematic sample is that validated models are not readily searchable as a distinct category and there are too many OD models overall to make reading them all feasible. Also, I suspect, validated models just remain rare in line with the larger scale findings of Dutton and Starbuck (1971, p. 130, table 1) and discouragingly, much more recently, Angus and Hassani-Mahmooei (2015, section 4.5, figure 9). Obviously, since part of the sample was selected by total number of citations, one cannot make a comparison on that basis, so instead I have used the best possible alternative (given the limitations of the sample) and compared articles on citations per year. The problem here is that attempting validated modelling is relatively new while older articles inevitably accumulate citations however slowly. But what I was trying to discover was whether new validated models could be cited at a much higher annual rate without reaching the top 50 (or whether, conversely, older articles could have a high enough total citations to get into the top 50 without having a particularly impressive annual citation rate.) One would hope that, ultimately, validated models would tend to receive more citations than those that were not validated (but see the rather disconcerting related findings of Serra-Garcia and Gneezy 2021). Table 1 shows the results sorted by citations per year.
Table 1. Annual Citation Rates for OD Articles Highly Cited in JASSS (Systematic Sample) and Validated OD Articles in or Cited in JASSS (Unsystematic Sample)
With the notable (and potentially encouraging) exception of Duggins (2017), the most recent validated OD model I have been able to discover in JASSS, the sample clearly divides into non-validated research with more citations and validated research with fewer. The position of Duggins (2017) might suggest greater recent interest in validated OD models. Unfortunately, however, qualitative analysis of the citations suggests that these are not cited as validated models per se (and thus as a potential improvement over non-validated models) but merely as part of general classes of OD model (like those involving social networks or repulsion – moving away from highly discrepant opinions). This tendency to cite validated models without acknowledging that they are validated (and what the implications of that might be) is widespread in the articles I looked at.
Obviously, there is plenty wrong with this analysis. Even looking at citations per annum we are arguably still partially sampling on the dependent variable (articles selected for being widely cited prove to be widely cited!) and the sample of validated OD models is unsystematic (though in fairness the challenges of producing a systematic sample are significant.[3]) But the aim here is to make a distinctive use of RoFASSS as a rapid mode of permanent publication and to think differently about science. If I tried to publish this in a peer reviewed journal, the amount of labour required to satisfy reviewers about the research design would probably be prohibitive (even if it were possible). As a result, the case to answer about this apparent (and perhaps undesirable) pattern in data might never see the light of day.
But by publishing quickly in RoFASSS without the filter of peer review I actively want my hypothesis to be rejected or replaced by research based on a better design (and such research may be motivated precisely by my presenting this interesting pattern with all its imperfections). When it comes to scientific progress, the chance to be clearly wrong now could be more useful than the opportunity to be vaguely right at some unknown point in the future.
Acknowledgements
This analysis was funded by the project “Towards Realistic Computational Models Of Social Influence Dynamics” (ES/S015159/1) funded by ESRC via ORA Round 5 (PI: Professor Bruce Edmonds, Centre for Policy Modelling, Manchester Metropolitan University: https://gtr.ukri.org/projects?ref=ES%2FS015159%2F1).
Notes
[1] Note that the validated OD models had their citations counted manually while the high total citation articles had them counted automatically. This may introduce some comparison error but there is no reason to think that either count will be terribly inaccurate.
[2] Including the year of publication and the current year (2021).
[3] Note, however, that there are some checks and balances on sample quality. Highly successful validated OD models would have shown up independently in the top 50. There is thus an upper bound to the impact of the articles I might have missed in manually constructing my “version 1” bibliography. The unsystematic review of 47 articles by Sobkowicz (2009) also checks independently on the absence of validated OD models in JASSS to that date and confirms the rarity of such articles generally. Only four of the articles that he surveys are significantly empirical.
References
Angus, Simon D. and Hassani-Mahmooei, Behrooz (2015) ‘“Anarchy” Reigns: A Quantitative Analysis of Agent-Based Modelling Publication Practices in JASSS, 2001-2012’, Journal of Artificial Societies and Social Simulation, 18(4), October, article 16, <http://jasss.soc.surrey.ac.uk/18/4/16.html>. doi:10.18564/jasss.2952
Bernardes, A. T., Costa, U. M. S., Araujo, A. D. and Stauffer, D. (2001) ‘Damage Spreading, Coarsening Dynamics and Distribution of Political Votes in Sznajd Model on Square Lattice’, International Journal of Modern Physics C: Computational Physics and Physical Computation, 12(2), February, pp. 159-168. doi:10.1140/e10051-002-0013-y
Bernardes, A. T., Stauffer, D. and Kertész, J. (2002) ‘Election Results and the Sznajd Model on Barabasi Network’, The European Physical Journal B: Condensed Matter and Complex Systems, 25(1), January, pp. 123-127. doi:10.1142/S0129183101001584
Brousmiche, Kei-Leo, Kant, Jean-Daniel, Sabouret, Nicolas and Prenot-Guinard, François (2016) ‘From Beliefs to Attitudes: Polias, A Model of Attitude Dynamics Based on Cognitive Modelling and Field Data’, Journal of Artificial Societies and Social Simulation, 19(4), October, article 2, <https://www.jasss.org/19/4/2.html>. doi:10.18564/jasss.3161
Caruso, Filippo and Castorina, Paolo (2005) ‘Opinion Dynamics and Decision of Vote in Bipolar Political Systems’, arXiv > Physics > Physics and Society, 26 March, version 2. doi:10.1142/S0129183105008059
Chattoe-Brown, Edmund (2014) ‘Using Agent Based Modelling to Integrate Data on Attitude Change’, Sociological Research Online, 19(1), February, article 16, <https://www.socresonline.org.uk/19/1/16.html>. doi:0.5153/sro.3315
Chattoe-Brown Edmund (2020) ‘A Bibliography of ABM Research Explicitly Comparing Real and Simulated Data for Validation: Version 1’, CPM Report CPM-20-216, 12 June, <http://cfpm.org/discussionpapers/256>
Deffuant, Guillaume (2006) ‘Comparing Extremism Propagation Patterns in Continuous Opinion Models’, Journal of Artificial Societies and Social Simulation, 9(3), June, article 8, <https://www.jasss.org/9/3/8.html>.
Deffuant, Guillaume, Amblard, Frédéric, Weisbuch, Gérard and Faure, Thierry (2002) ‘How Can Extremism Prevail? A Study Based on the Relative Agreement Interaction Model’, Journal of Artificial Societies and Social Simulation, 5(4), October, article 1, <https://www.jasss.org/5/4/1.html>.
Duggins, Peter (2017) ‘A Psychologically-Motivated Model of Opinion Change with Applications to American Politics’, Journal of Artificial Societies and Social Simulation, 20(1), January, article 13, <http://jasss.soc.surrey.ac.uk/20/1/13.html>. doi:10.18564/jasss.3316
Dutton, John M. and Starbuck, William H. (1971) ‘Computer Simulation Models of Human Behavior: A History of an Intellectual Technology’, IEEE Transactions on Systems, Man, and Cybernetics, SMC-1(2), April, pp. 128-171. doi:10.1109/TSMC.1971.4308269
Flache, Andreas, Mäs, Michael, Feliciani, Thomas, Chattoe-Brown, Edmund, Deffuant, Guillaume, Huet, Sylvie and Lorenz, Jan (2017) ‘Models of Social Influence: Towards the Next Frontiers’, Journal of Artificial Societies and Social Simulation, 20(4), October, article 2, <http://jasss.soc.surrey.ac.uk/20/4/2.html>. doi:10.18564/jasss.3521
Fortunato, Santo and Castellano, Claudio (2007) ‘Scaling and Universality in Proportional Elections’, Physical Review Letters, 99(13), 28 September, article 138701. doi:10.1103/PhysRevLett.99.138701
Hegselmann, Rainer and Flache, Andreas (1998) ‘Understanding Complex Social Dynamics: A Plea For Cellular Automata Based Modelling’, Journal of Artificial Societies and Social Simulation, 1(3), June, article 1, <https://www.jasss.org/1/3/1.html>.
Hegselmann, Rainer and Krause, Ulrich (2002) ‘Opinion Dynamics and Bounded Confidence Models, Analysis, and Simulation’, Journal of Artificial Societies and Social Simulation, 5(3), June, article 2, <http://jasss.soc.surrey.ac.uk/5/3/2.html>.
Salzarulo, Laurent (2006) ‘A Continuous Opinion Dynamics Model Based on the Principle of Meta-Contrast’, Journal of Artificial Societies and Social Simulation, 9(1), January, article 13, <http://jasss.soc.surrey.ac.uk/9/1/13.html>.
Serra-Garcia, Marta and Gneezy, Uri (2021) ‘Nonreplicable Publications are Cited More Than Replicable Ones’, Science Advances, 7, 21 May, article eabd1705. doi:10.1126/sciadv.abd1705
Sobkowicz, Pawel (2009) ‘Modelling Opinion Formation with Physics Tools: Call for Closer Link with Reality’, Journal of Artificial Societies and Social Simulation, 12(1), January, article 11, <http://jasss.soc.surrey.ac.uk/12/1/11.html>.
Urbig, Diemo, Lorenz, Jan and Herzberg, Heiko (2008) ‘Opinion Dynamics: The Effect of the Number of Peers Met at Once’, Journal of Artificial Societies and Social Simulation, 11(2), March, article 4, <http://jasss.soc.surrey.ac.uk/11/2/4.html>.